机器学习与社会计算范式革新
AI + 计算社会科学微专业
Part 1计算社会科学的兴起
传统社科研究的标准流程
这个流程运转了一百年,效果很好
提出框架
可检验命题
问卷 / 访谈
回归 / t 检验
支持 / 拒绝
但它有天花板。
三个天花板
你有 10 万条微博,传统方法看不完。
热点话题结束了,论文还在审稿。
10 个人标注同一条微博,可能给出 5 种判断。
打破天花板:计算社会科学
Computational Social Science
利用数字痕迹(社交媒体、通话记录、政府文件、搜索记录……)
和计算方法(机器学习、NLP、网络分析……)
研究以前无法研究的社会现象。
2009 年,David Lazer 等 15 位学者在 Science 发表宣言:
“a computational social science is emerging”
Lazer et al., “Computational Social Science,” Science 323, 2009
“Text as Data” — 文本变成数据
Grimmer & Stewart (2013) 提出了一个影响深远的主张:
以前
质性材料,不能直接做统计
规模上限:几十篇 / 几百篇
现在
可以量化、分类、建模
规模上限:几百万篇
Grimmer & Stewart, “Text as Data,” Political Analysis 21, 2013
如果你今天要处理 10 万条文本
先不要想论文,先想一个很多单位已经会遇到的真实任务
哪些最紧急?哪些值得优先处理?
情绪在变吗?风险在哪里?
能不能先自动归类、摘要、提炼重点?
怎么让系统先帮你读、找主题、找异常?
什么是“范式革新”
不只是
更快地分析数据
自动化重复劳动
范式革新
能看到以前看不到的模式
能构建以前无法测量的变量
Thomas Kuhn:范式转移不是改进,是换一种方式看世界。
今天的三个核心问题
Part 2从小样本到全样本
传统研究:抽样推断
你想了解的对象
N = 500–3,000
从样本推总体
这个逻辑完全合理——如果你没办法看完所有数据。
但它有代价:
少数群体和极端值
代表总体吗?
其余 99.99% 丢弃了
当你能分析所有数据
传统抽样
依赖代表性假设
看不到长尾和极端值
——————
问题受限于数据规模
全量分析
无需抽样假设
发现长尾、异常值、微小群体
——————
问题不再受数据限制
关键不只是“更多”——是从切片变成全景。
Case: 7,200 万人的友谊网络预测阶层流动
发现:经济连接度是预测向上流动最强的单一变量(相关度高达 0.65)——比学校支出、种族构成、不平等程度都强。没有全量社交网络数据,这个变量根本不存在。
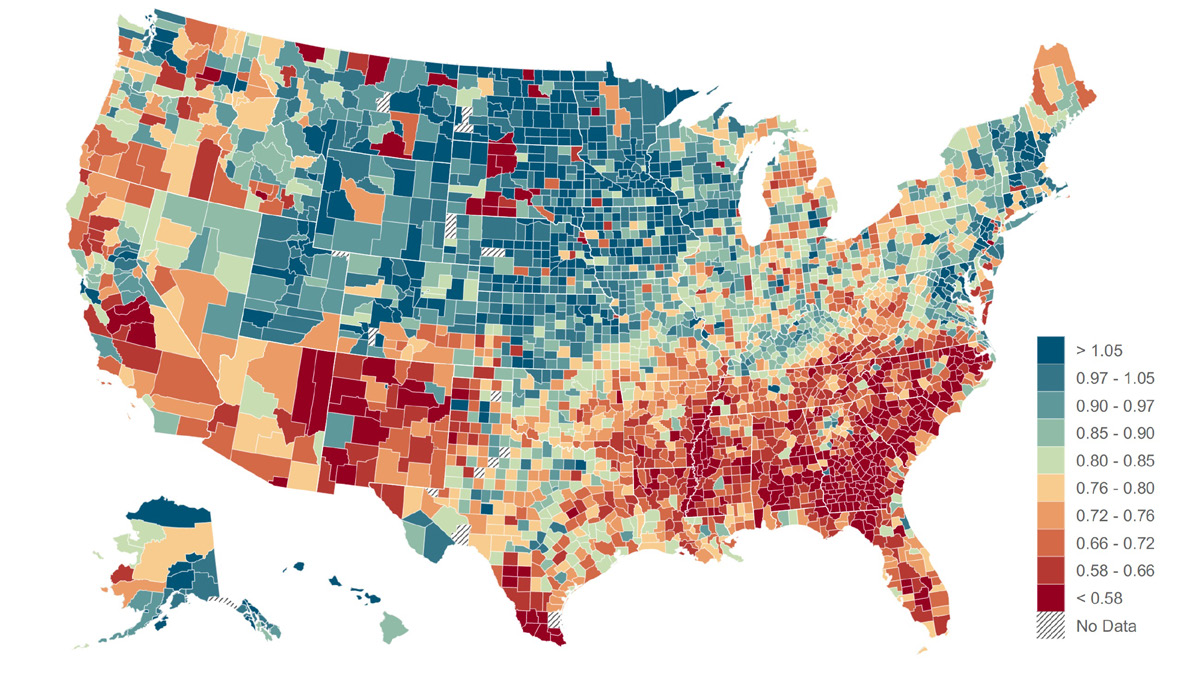
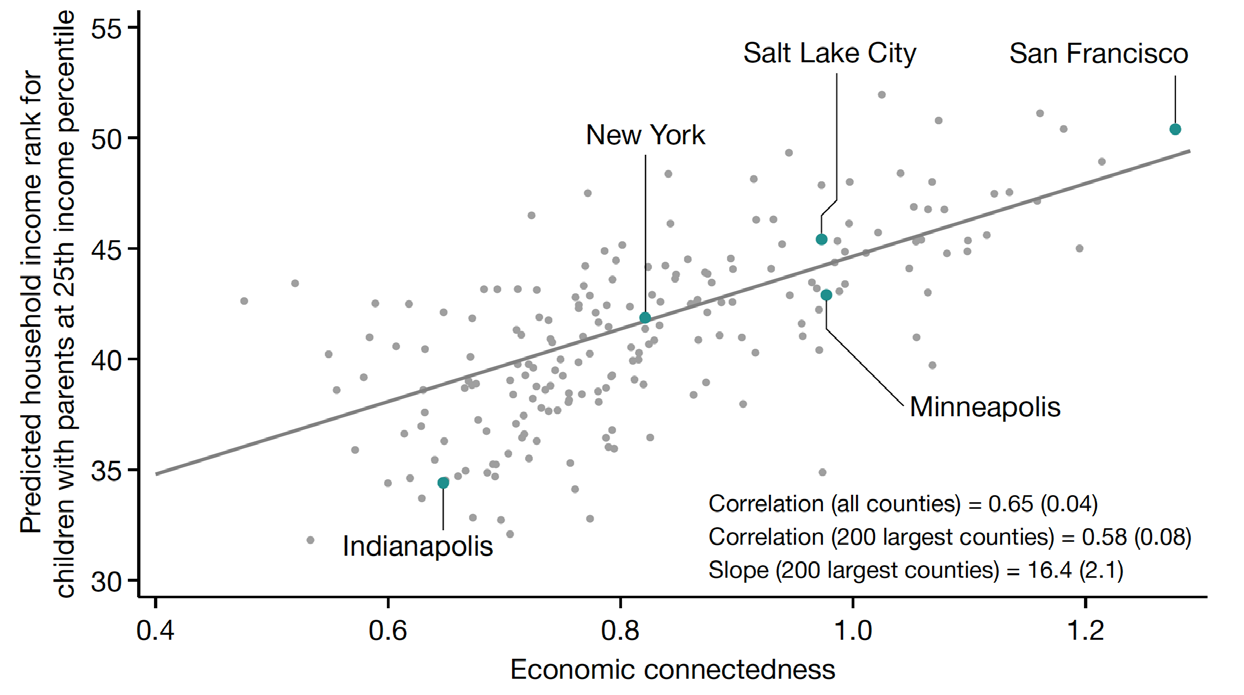
想一想:如果你能拿到中国的类似全量数据,你会研究什么社会现象?
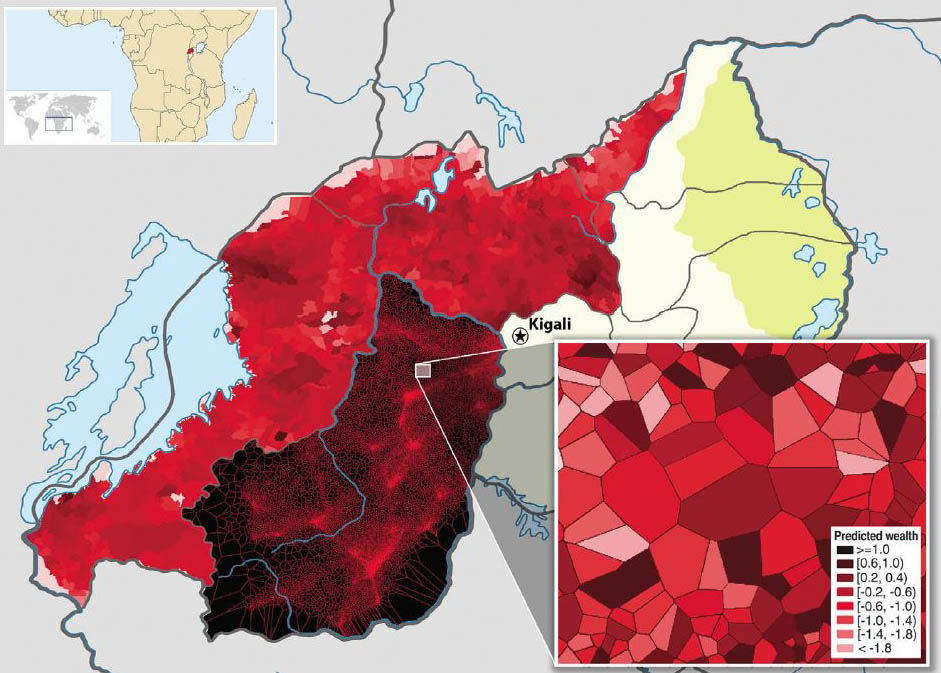
Case: 手机通话记录预测贫困
Blumenstock, Cadamuro & On (2015) 用卢旺达 150 万手机用户的通话记录,训练模型预测每个人的财富水平。
启示:传统调查只能覆盖几千户,这里覆盖了全国。不是更快做同一件事——是能做到以前做不到的全覆盖。
Blumenstock, Cadamuro & On, Science 350, 2015
规模带来的质变
从“更多数据”到“不同的研究逻辑”
当你能分析所有数据,
瓶颈不再是“能采集多少”,
而是“能问什么问题”。
规模革命不是让旧研究跑得更快,
而是让全新的研究问题成为可能。
接下来 → 第二个范式转变
Part 3从解释到预测
社科的默认范式:因果解释
社会科学的核心追求:X 为什么导致 Y?
这很重要。但——这是唯一重要的事吗?
预测有什么用?
有些政策问题的核心不是“为什么”,而是“谁”和“什么时候”
政策的关键是先准确判断资源给谁,而不一定先解释全部因果机制。
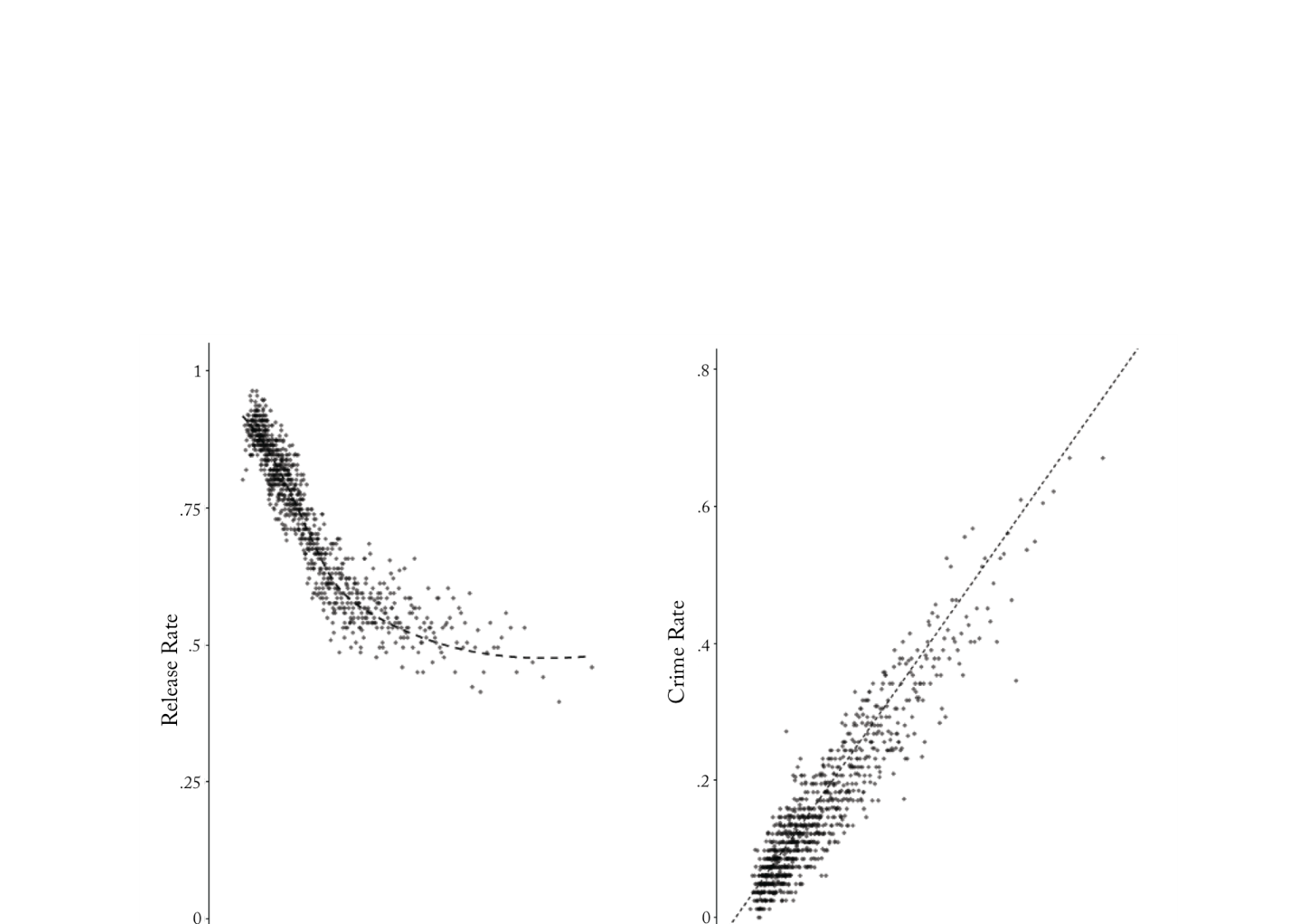
Case: 算法揭示法官的系统性偏差
Kleinberg, Lakkaraju, Leskovec, Ludwig & Mullainathan (2018)
用 ML 预测纽约市 75 万名被告的逃跑/再犯风险。
启示:这里预测本身就是发现。不需要知道“为什么”法官有偏差,只要预测足够准确,就能用对比揭示问题。
Kleinberg et al., “Human Decisions and Machine Predictions,” QJE 133(1), 2018
Case: 160 个团队预测人生结局——结果令人意外
Salganik et al. (2020) 发起 Fragile Families Challenge:给 160 个研究团队同一份丰富的面板数据(4,242 个家庭、12,942 个变量、15 年追踪),预测 6 个人生结局:GPA、是否留级、物质困难、被驱逐、失业、是否受训练。
最多能解释约 20% 的差异
最多也只能解释约 5% 的差异
彼此差异极小 → 瓶颈不在算法,在数据
Salganik et al., “Measuring the predictability of life outcomes,” PNAS 117(15), 2020
预测 vs 解释:不是对立
解释(Explanation)
目标:理论建构
优先:无偏估计
“教育为什么影响收入”
预测(Prediction)
目标:准确判断
优先:泛化能力
“谁最可能辍学”
先用预测模型定位问题,再用因果推断解释问题。
想一想你关注的一个政策领域——瓶颈是预测(“对谁做”)还是解释(“为什么做”)?
什么时候值得用 ML / agent 做预测?
先问一句:你面对的是不是“先处理谁、先看哪里、先把什么变成标签”的问题?
不是所有人都能先服务、先跟进、先干预。
模型先帮你排优先级。
例:哪些工单、病人、学生最需要优先关注
文本、图像或记录先被转成
情绪、满意度、风险级别等变量。
例:把评论变成“正面 / 中性 / 负面”或“高风险 / 低风险”
先用模型快速筛出重点人群、文本或地区,
再让专家进一步判断。
例:先找高风险案例,再做人工研判或正式评估
学术上这类用途可对应政策定向、变量构建和研究辅助。
对今天这批学习者,更重要的是先记住:模型常常先帮你“筛”,人再决定怎么“用”。
预测不是社科的敌人。
当政策问题的核心是“对谁做”而不是“为什么做”时,
准确预测就是最有价值的答案。
解释和预测是互补的,不是对立的。
接下来 → 第三个范式转变
Part 4测量不存在的变量
先看一个今天就能上手的 LLM / agent 流程
把“看不完的材料”先变成“可处理的标签”
工单、评论、报告、访谈
摘要、分类、找异常
主题、情绪、风险分数
谁先处理、哪里追问、何时升级
接下来再看:这种能力在学术上为什么重要,它和传统测量有什么本质差别。
传统测量的困境
社科研究中最重要的概念,往往最难测量
共同问题:概念重要,但测量手段受限。
把模糊概念变成可用标签的三条路
告诉系统“什么算正面、什么算风险、什么算投诉”。
然后把同样标准扩展到更大数据。
学术上常叫:有监督分类
让系统先找“哪些内容彼此更像”。
它适合用来发现你原本没想到的结构。
学术上常叫:无监督发现
直接用自然语言描述任务,让 LLM 或 agent 先判断。
速度快,但更依赖提示设计和人工复核。
常见形式:LLM / agent 零样本判断
真实工作里,这三种方法往往不是三选一,而是串起来用。
Case: 你关注谁,暴露了你的立场
Barberá (2015) 提出:Twitter 用户的关注列表就是一种“投票行为”——关注了谁,等价于一次意识形态投射。
FOX、Trump、NRA
推断立场坐标
与投票记录高度吻合
这个方法可以给任何 Twitter 用户打分——数百万普通公民第一次有了意识形态坐标。
Barberá, “Birds of the Same Feather Tweet Together,” Political Analysis 23(1), 2015
Case: 国会的语言正在分裂
Gentzkow, Shapiro & Taddy (2019) 用 ML 分析 1873–2016 年美国国会所有发言记录,训练模型仅凭一段话的用词就判断说话者的党派。
模型准确率接近随机猜测(~55%)。
语言上,两党是“一家人”。
一段话就能判断是共和党还是民主党。
语言本身变成了党派标签。
不需要问卷、不需要投票数据——语言本身就是证据。
Gentzkow, Shapiro & Taddy, “Measuring Group Differences in High-Dimensional Choices,” Econometrica 87(4), 2019
Case: 打破回音室反而加剧了极化
Bail et al. (2018) 在 Twitter 上做了一个田野实验:让民主党和共和党用户关注一个发布对立观点的机器人账号,持续一个月。
关注自由派机器人
态度没有趋中
没有自动化机器人和 NLP 态度测量,这个实验根本无法执行。
Bail et al., “Exposure to opposing views on social media can increase political polarization,” Science 361, 2018
测量革新的共同模式
三个案例,同一个逻辑:把“行为痕迹”变成“测量变量”
被 ML 转化为以前不存在的测量变量。
你的研究领域里,有哪些“行为痕迹”可以被转化为测量变量?
从发现到确认:无监督学习的角色
有时候你不知道数据里有什么——这也是一种测量
把 10 万条文本扔进主题模型 → 发现 20 个主题
哪些主题有理论意义?哪些只是噪音?
用有监督方法在更大数据集上确认发现
Molina & Garip, “Machine Learning for Sociology,” Annual Review of Sociology 45, 2019
Case: ML 发现社会流动的“隐藏类型”
Molina & Garip (2019) 使用聚类算法分析墨西哥-美国移民数据,发现传统理论框架遗漏的群体特征。
传统回归分析
“教育↑ → 移民概率↓”
平均效应掩盖了群体异质性
ML 聚类分析
每种是多个变量的组合
传统方法看不到的子群体
→ 合法移民
→ 非正式迁移路径
研究里还发现了其他类型。真正要记住的不是“总共有几类”,
而是平均效应背后,可能藏着多条不同的组合路径。
ML 让我们能构建
以前根本无法量化的概念。
意识形态、文化含义、情感倾向——
这些不再是“只能定性讨论”的模糊概念,
而是可以大规模、跨时间、跨国比较的变量。
接下来 → 方法论反思
Part 5方法论反思
ML 在研究中的三种角色
先别急着记术语,先分清你现在把 ML 当成什么工具。
例:情感分析、意识形态打分、文化含义追踪。
先问:你测到的真的是你想测的吗?
例:主题模型、聚类、异常检测。
先问:这是真实模式,还是数据噪声?
例:政策定向、风险评估、变量构建。
先问:换个场景、时间或部门还准不准?
把 LLM / ML 用进工作前,先问这四个问题
对应:效度。高准确率不等于高效度,模型可能学到的是捷径。
2. 换个时间、部门或城市还准吗?
对应:泛化与可复现性。一次跑通,不代表处处都成立。
对应:可解释性。尤其在政策或管理场景里,黑箱往往不够。
4. 它会不会放大偏见、伤到某些人?
对应:伦理与偏见。数据代表谁、不代表谁,决定了结果会偏向谁。
好用的工具,不等于可以不经复核地直接使用。
对这批学习者来说,最重要的不是先学会“最复杂的模型”,而是先学会“怎样安全地用它”。
讨论
想一想你自己的研究问题——
ML 能帮到你吗?
今日要点
下节课预告
第四课 有监督机器学习技术
今天讨论了 ML 改变了什么,
下节课回到技术层面——
具体怎么做分类和标注,以及怎样把大模型当作标注助手。
课前思考:你自己的研究问题里,有哪些概念需要被“测量”?
带着这个问题来上课