无监督机器学习技术
让数据自己说话
一个贯穿本课的信念
“All models are wrong,
but some are useful.“
— George Box,统计学家,1976
今天的方法不会告诉你“正确答案”
它只会从数据里找出有用的结构。
你负责判断这个结构对你的业务有没有意义
上节课遗留的问题
有监督学习第四课
“好的内容”由人来定义
标注成本高、覆盖有限
现实业务难题
海量政策文件,没人读完
几十万微博,谁来打标签?
今天的核心问题:没有标签,机器能发现什么?
今天的路线图
文档里藏着什么话题?
词是向量,语义是距离
你能用这些做什么?
让 NLP 自主行动
贯穿全课的问题:无监督 = 发现隐藏结构 | 压轴:智能体如何整合所有 NLP 技术
Part 1 / 3
主题模型:
发现文本的话题结构
你面对的真实场景
共同困境:文本太多,人工无法逐条阅读,但又没有预设的分类标签
主题模型的直觉
想象你在看 100 篇微博:
话题 A:医疗
高频词:挂号、医生、检查、费用、等待
话题 B:教育
高频词:作业、考试、补课、老师、成绩
话题 C:交通
高频词:堵车、地铁、限行、停车、违章
LDA 的工作
1. 你告诉它:找 k 个话题
2. 它自动发现:每个话题由哪些词构成
3. 以及:每篇文章讲了多少比例的每个话题
模型不知道“医疗”这个名字
你读到词就知道了
LDA 的核心机制:掷骰子
每篇文章都像一个人,口袋里揣着几枚“话题骰子”:
每一个词,都是“掷骰子”决定来自哪个话题
狄利克雷分布的直觉
就是描述“骰子的形状”:
一篇文章里各话题比例的先验分布
参数 α 小 → 话题集中(纯粹型文章)
参数 α 大 → 话题分散(混合型文章)
模型通过反复调整每个词的话题归属,
逐渐找到最符合所有文章的那套话题分配
想想看:如果你的工作文本有 6 个话题,第 7 个话题会是什么?
案例:国会演讲里藏着什么话题?
对第 109 届国会(2005–2007 年)美国参议员的所有新闻稿运行 LDA,无需人工预设分类
语料:约 24,000 份文件 | 方法:LDA(贝叶斯主题模型)
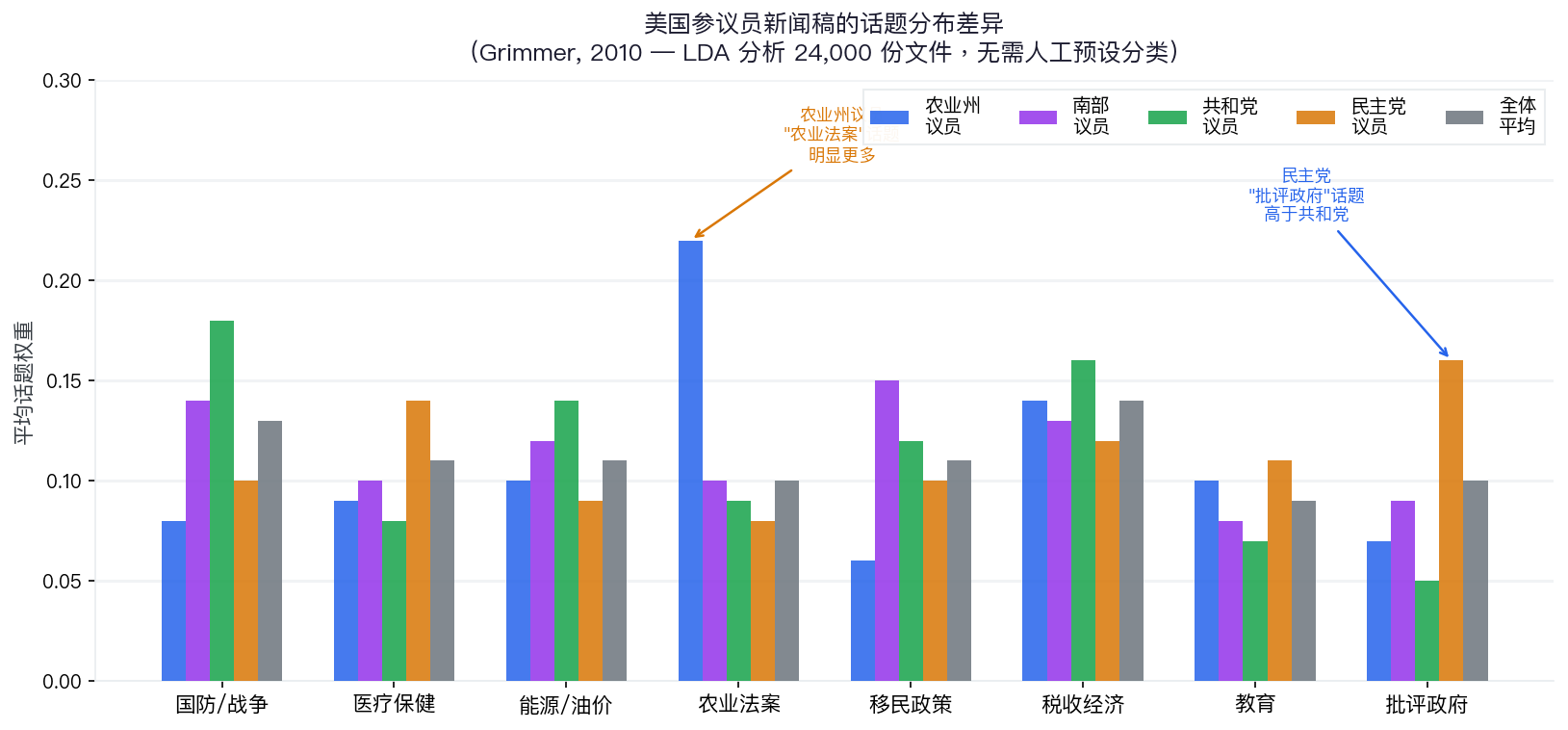
农业州议员在“农业法案”话题权重明显更高;民主党在“批评政府”话题高于共和党。模型自己发现的,无需人工标注
Grimmer, J. (2010). A Bayesian hierarchical topic model for political texts. Political Analysis, 18(1), 1–35.
实操:sklearn 三步走
分词 / 构建词矩阵
设定 k 个话题
读词 / 给话题命名
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
# 1. 构建词频矩阵
vectorizer = CountVectorizer(max_df=0.9, min_df=2)
X = vectorizer.fit_transform(texts) # texts = 分词后的字符串列表
vocab = vectorizer.get_feature_names_out()
# 2. 训练 LDA,指定话题数 k — [注] k 由你来定,模型无法自行决定最佳值
lda = LatentDirichletAllocation(n_components=4, random_state=42)
lda.fit(X)
# 3. 查看每个话题的前 10 个词(不需要手写此代码,理解每步做什么即可)
for i, comp in enumerate(lda.components_):
top_words = vocab[comp.argsort()[::-1][:10]]
print(f"话题 {i}: {' | '.join(top_words)}")演示结果:政务新闻语料 LDA(k=4)
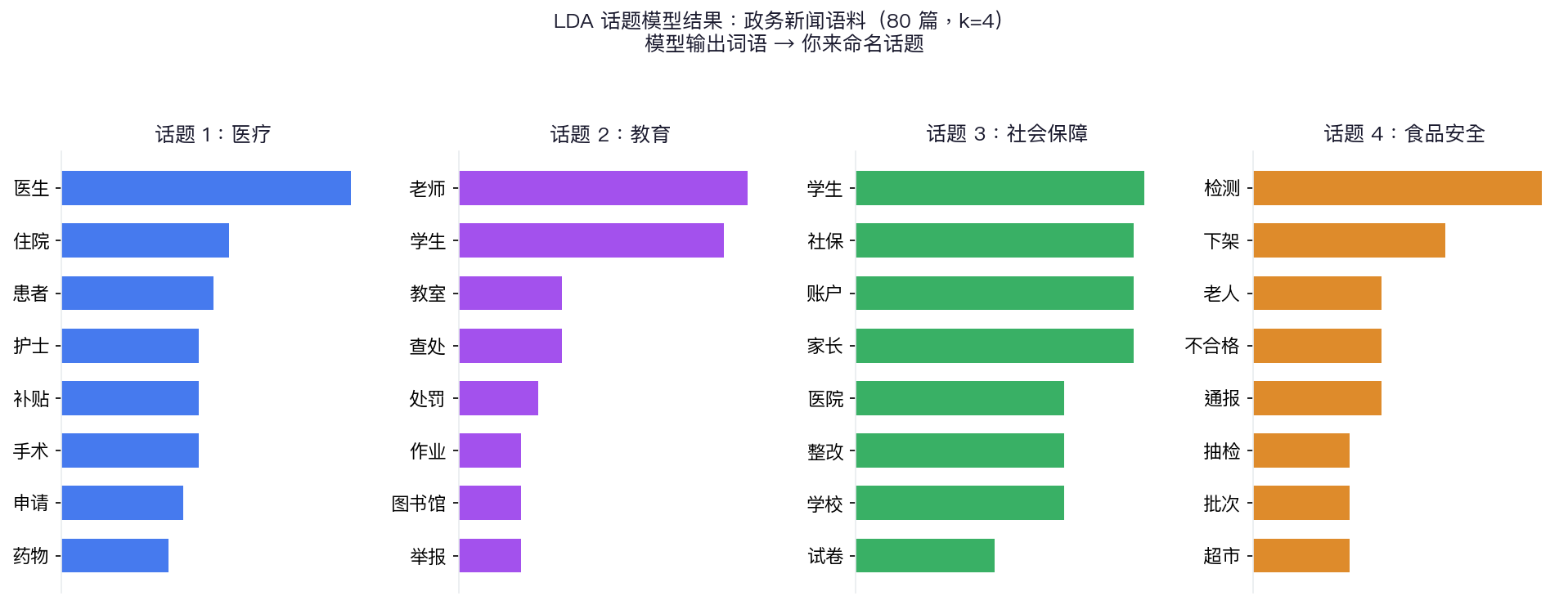
话题1(医生/住院/患者/手术)→ 你命名为“医疗”|话题4(检测/下架/抽检/超市)→ 你命名为“食品安全”
模型自动发现了这 4 个结构,命名工作由你来完成
使用 sklearn.decomposition.LatentDirichletAllocation,n_components=4,random_state=42
LDA 的核心局限
① 话题数 k 靠人设定
设 k=6 和 k=12,结果完全不同。没有“正确答案”,只有“对你有用”的答案
② 忽略词序
“感谢医生,不满意收费”与“不满意医生,感谢收费”被视为完全一样的文档,顺序和语气消失了
③ 不理解词义
“苹果”在科技与饮食语境被视为同一词。这是下节课词嵌入要解决的问题
解读必须靠领域知识
模型输出一堆词
你才知道这个话题叫“医疗投诉”还是“卫生监管”
没有领域知识,模型是失效的
All models are wrong —
你的判断是让它变得 useful 的关键
如果你要追踪话题随时间的变化,
还需要对齐每次运行的话题编号,这是额外工作
LDA:从一堆文本里
自动找出话题结构
不需要标签,不需要预设分类
输入文本 → 输出“哪些词属于哪些话题”
你来解读,你来命名
PART 2 → 如果词本身也能变成数字,会发生什么?
Part 2 / 3
词嵌入:
词是向量,语义是距离
LDA 留下了一个缺口
LDA 对词的认知
“苹果”(水果)和“苹果”(品牌)= 完全相同
词与词之间没有距离、没有关系
我们想要的
语义关系可以计算、可以测量
词嵌入:把每个词变成一个向量
一张图说清楚词嵌入
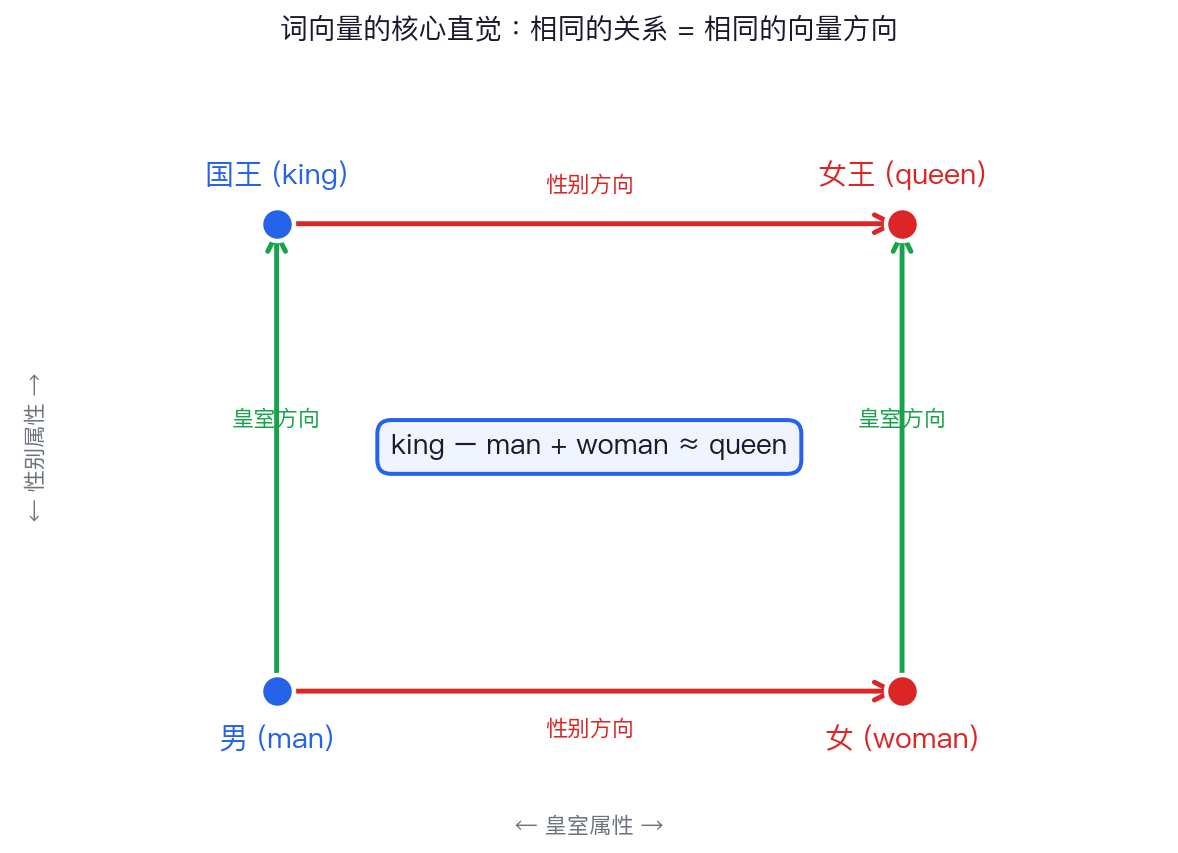
红色箭头(性别方向):man→woman 与 king→queen 完全平行、完全等长
绿色箭头(皇室方向):man→king 与 woman→queen 完全平行、完全等长
核心洞见:相同的语义关系 = 相同的向量方向
换个场景,结构完全一样
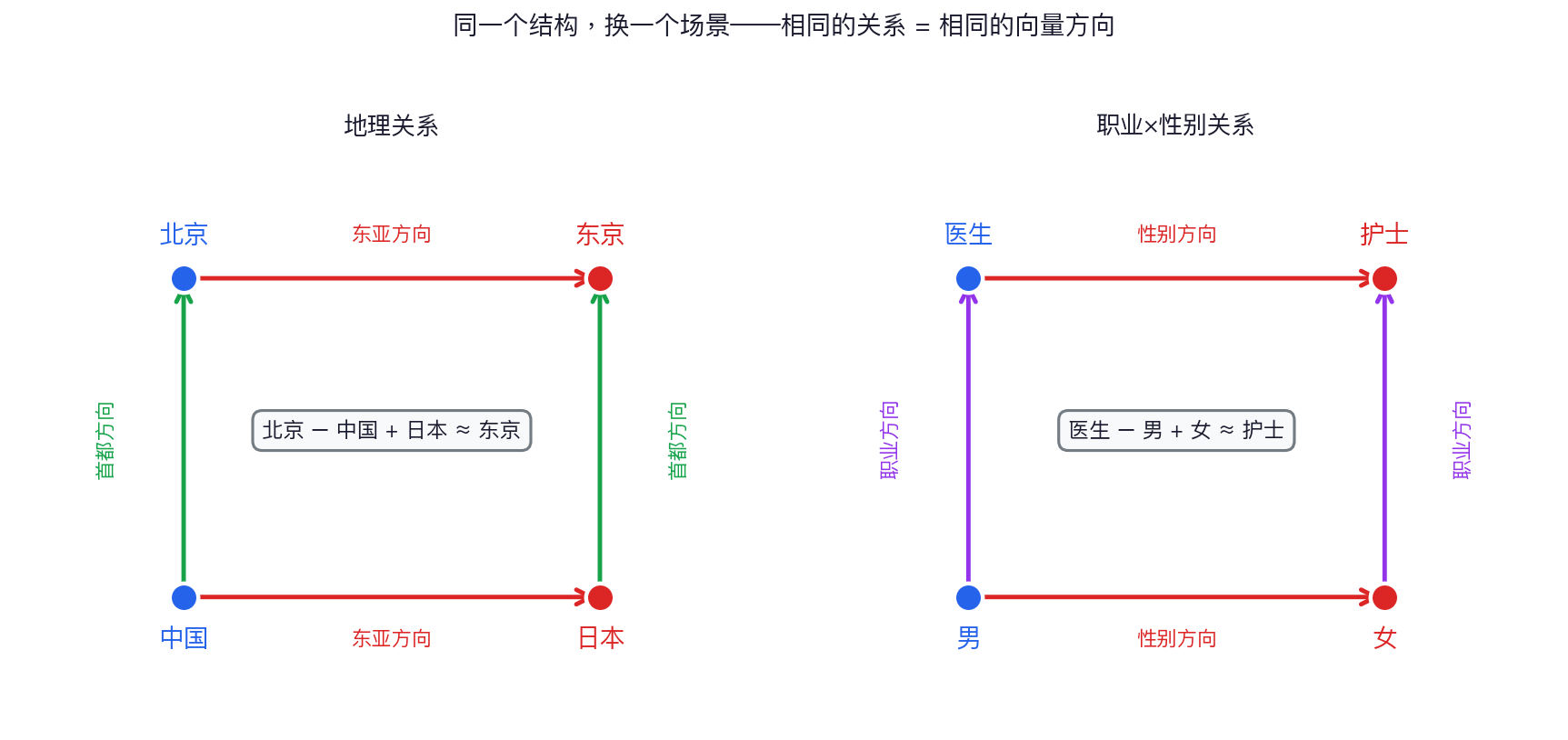
左:地理关系(首都方向) 右:职业×性别关系(性别方向)
右图的“医生−男+女≈护士”揭示了训练数据里的性别刻板印象。这正是 Garg et al. (2018) 追踪 100 年的研究对象
最后那个例子让你感到意外吗?语言里还藏着哪些类似的偏见?
用数学写出来就是这样
图里的平行四边形,用向量算术表达就是:
这是因为模型在训练时把相同语境下出现的词学到了相近的位置。图里的平行四边形,就是训练的结果在空间里的投影。
模型怎么学会这个空间?
Word2Vec(CBOW):给定上下文,预测空缺词
“患者 [?] 反映 床位 紧张“ → 预测 [?] → 反复数十亿次 → 空间逐渐成形
无需标注
反复迭代
平行四边形自然涌现
训练完全无监督。模型从来没人告诉它“king 和 queen 的关系类似 man 和 woman”,它自己学会的
图表解读:职业词的性别偏见如何变化
越靠近正值 = 越偏向“男性职业”,越靠近负值 = 越偏向“女性职业”
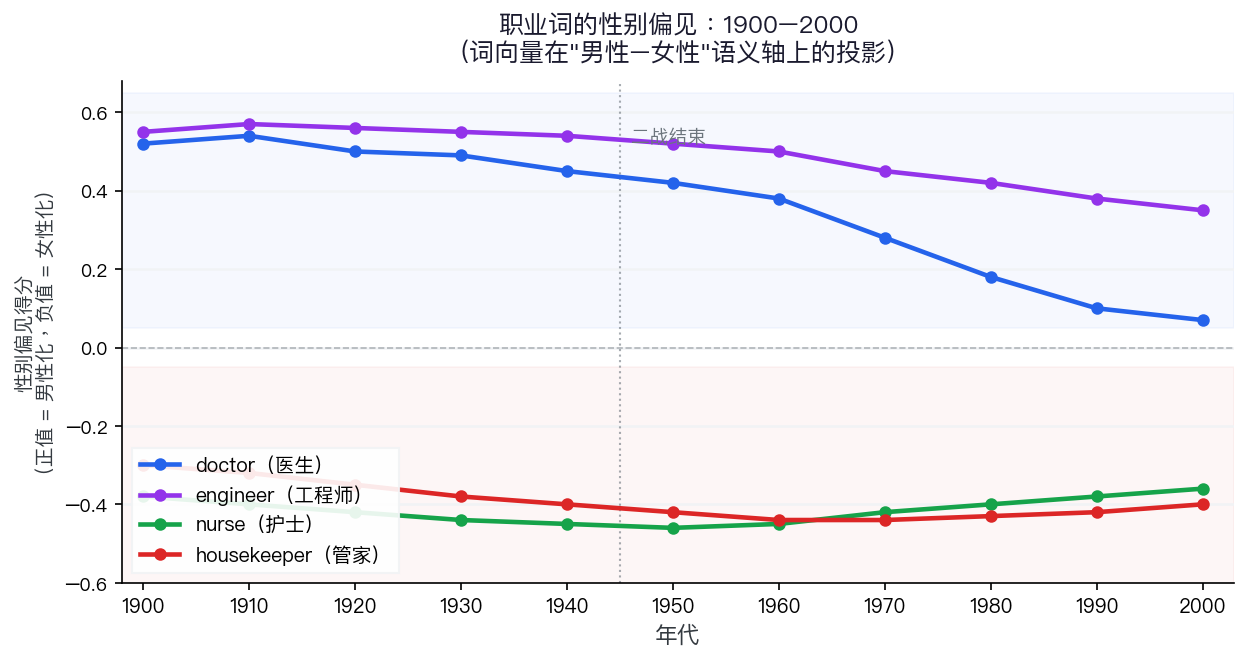
1960 年代以前,几乎所有“高技能职业”词都偏向男性;二战后 doctor 的男性偏见显著收窄,但 housekeeper 的女性化关联在部分时期仍维持或加强
[注] 示意图:数据依据 Garg et al. (2018) 图1公布数值重建,非原图
Garg et al. (2018), PNAS
图表解读:族裔刻板印象的百年变迁
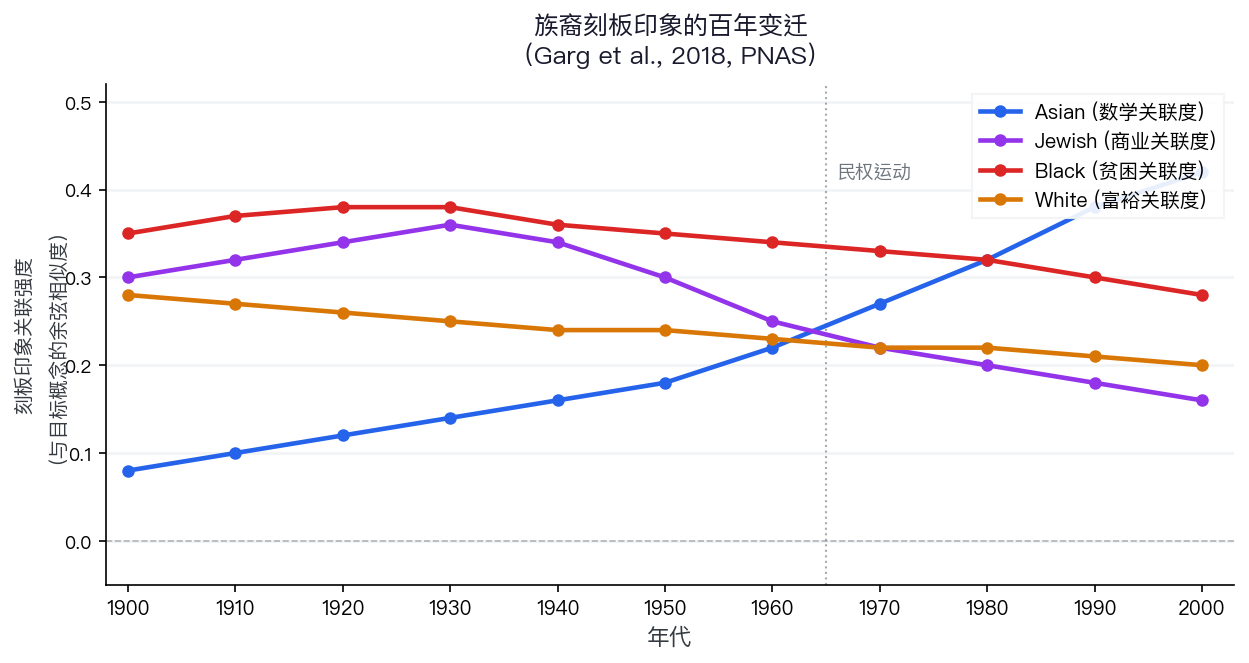
Asian 与“数学”的关联在 1960 年代以后才显著上升。刻板印象并非一直存在,它是历史建构的产物
[注] 示意图:依据 Garg et al. (2018) 结论重建,趋势方向忠实于原文,具体数值为近似
Garg et al. (2018), PNAS
你的行业里,有没有类似的刻板印象藏在数据里?
实操:加载词向量(gensim)
# 安装:pip install gensim
import gensim.downloader as api
# 课堂演示推荐轻量模型(50 维,解压约 66 MB)
model = api.load("glove-wiki-gigaword-50")
# 加载大模型时用(300 维,解压约 3.6 GB,课堂网速需确认)
# model = api.load("word2vec-google-news-300")
# ① 查询最相似的词(先检查词是否存在)
if "doctor" in model:
model.most_similar("doctor", topn=5)
# → [('physician', 0.83), ('nurse', 0.79), ...]
# ② 词向量算术
model.most_similar(positive=["king", "woman"], negative=["man"], topn=1)
# → [('queen', 0.71)]
# ③ 语义相似度
model.similarity("doctor", "nurse") # → 0.79
model.similarity("doctor", "apple") # → 0.09此处加载的是 GloVe 向量(基于全局词共现统计),与 Word2Vec(基于局部预测)属同类静态词嵌入,most_similar / similarity 用法相同。
50 = 向量维度;glove-wiki-gigaword-50 约 66MB,课堂演示推荐;不需要手写,理解每步做什么即可
词嵌入的可视化:t-SNE
把高维词向量(如 50 维或 300 维)压缩到 2 维,让你能“看见”语义空间:
医疗类词聚在一起
政治类词聚在一起
数字类词聚在一起
相似的词自动形成“星座”
t-SNE 只是用来“看”的
真正的语义是在高维空间里
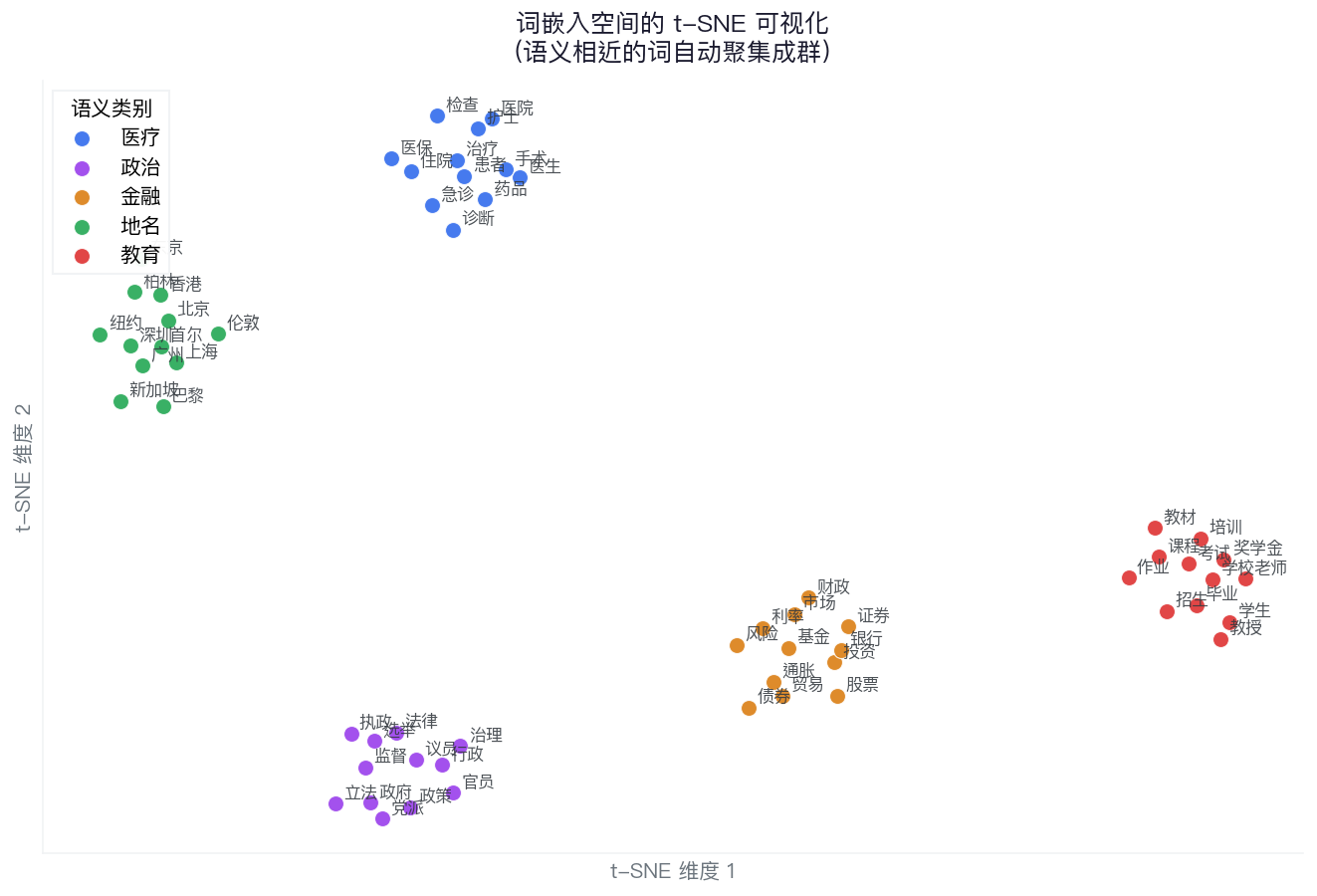
t-SNE 把 300 维词向量降到 2 维,语义相近的词聚在一起
[注] 示意图:基于合成向量生成,展示 t-SNE 聚类原理,非预训练模型实际输出
词嵌入的核心局限
① 一词一义:无法处理多义词
“苹果”在 Word2Vec 里只有一个向量,但在“苹果公司发布会”和“苹果树上结满苹果”里含义完全不同
② 刻板印象被放大
如 Garg 所示:语料中有什么偏见,模型就学进什么。用词嵌入筛选简历可能系统性歧视某类群体
③ 专业术语效果差
通用模型不认识“肠系膜”“窦性心律”等专业词,医疗/法律等场景需要领域专用预训练模型
领域知识仍不可替代:你需要判断哪些“相似”在你的场景里有意义
词嵌入:
把语言变成可计算的几何空间
相似的词 → 空间中相近的点
语义关系 → 向量运算
无监督训练,捕捉人类语言的深层规律
PART 3 → 行业应用 | PART 4 → AI 智能体
Part 3 / 4
行业应用:
你会用这些做什么?
两个工具,各有所长
LDA 主题模型
不需要标注,输入即可跑
适合:舆情分类、议题分析
文本聚类、政策归档
词嵌入
支持相似词查找、语义搜索
适合:智能搜索、用语分析
偏见检测、语义对比
很多真实项目会两个一起用:词嵌入提升文本表示质量,LDA 对话题做结构化发现
行业应用:医疗
管理层无需逐条阅读,即可掌握主要投诉分布
系统自动匹配“腹痛、消化道、胃部不适”等相关词
提升病历检索和导诊准确率
LDA 追踪不同时期报告的话题分布变化
最好训练领域专用词向量,或使用医疗预训练模型
行业应用:政府 · 金融 · 教育
一个完整的无监督分析流水线
问卷/热线/报告
去停词/标准化
发现话题结构
理解语义关系
命名 / 验证
资源/策略
人工解读是最关键的一步 — 模型找出结构,你来判断“这个话题叫什么”、“这个结果有没有意义”
这套流程可以无标签冷启动,落地高风险业务(医疗、金融)仍需人工抽检和合规评估
Part 4 / 4
AI 智能体:
让 NLP 自主行动
从工具到智能体:关键的一跃
传统 AI 工具
每次任务彼此独立
被动响应,不主动规划
例:情感分类器、翻译 API
AI 智能体(Agent)
调用工具、执行操作、观察反馈
根据结果动态调整策略
主动行动,直到目标完成
智能体不只是"升级版聊天机器人"——它能分解任务、调用外部工具、多轮迭代修正,就像能独立工作的助理
智能体的工作循环:ReAct 模式
读取输入
检索记忆
LLM 推理
规划下一步
调用工具
写入/输出
检查结果
↩ 继续循环
智能体的四个核心组件
GPT / Claude / DeepSeek 等大模型
今天学的所有 NLP 技术在这里汇聚
让智能体能读写外部系统
突破"只会说话"的根本限制
长期:向量数据库(存的正是词向量!)
语义检索:找到最相关的历史信息
管理依赖 / 错误恢复 / 并行执行
多智能体:不同专长的 Agent 分工合作
真实案例:OpenClaw 智能体平台
OpenClaw 是什么?
对话智能体构建平台
支持创建有性格、记忆、工具的 AI 角色
底层:LLM + 向量记忆 + 工具调用
场景:AI 伴侣 / 客服 / 领域助手
实例:王一博 Bot
部署在 OpenClaw 的对话 Agent
有固定的性格设定和长期记忆
记住用户偏好,跨对话持续交互
底层 NLP 技术如何运作
核心挑战:让 Agent 记住用户,同时不越过隐私边界
NLP 技术如何支撑智能体
RAG(检索增强生成) = 词嵌入检索相关文档 → 填入 LLM 上下文 → 生成准确回答
目前企业部署 AI 客服和知识库问答最主流的方案
多智能体系统:分工合作
为什么需要多个 Agent?
单一 Agent 能力有限
复杂任务需要专业分工
并行执行大幅提升效率
一个 Agent 的输出是另一个的输入
本课使用的 OpenMAIC 平台
Multi-Agent Interactive Classroom
多个教学 Agent 协作:
讲解 Agent + 提问 Agent + 评估 Agent
你正在用多智能体系统上课
任务分配
RAG 知识库
生成回答
质量把关
最终输出
智能体的现实挑战
① 幻觉(Hallucination)未解决
LLM 会自信地编造不存在的信息。智能体多步骤操作会让幻觉累积放大——金融、医疗等高风险场景必须保留人工核查
② 工具失败与不可预测性
外部 API 超时、代码执行报错、工具返回意外结果……智能体的鲁棒性远不如人类助理,业务部署前必须大量测试
③ 成本与延迟
多轮 LLM 调用叠加工具调用,成本高、响应慢。一个复杂任务可能触发十几次 API 调用,费用快速累积
结论:智能体是强大的新工具,但"All models are wrong"依然适用——人工监督和业务验证不可缺少
智能体:
NLP 技术的集大成者
LDA + 词嵌入 → 记忆与检索(RAG)
分类器 → 意图识别与情感感知
LLM → 推理、规划、生成
你学的每一项 NLP 技术,都是智能体能力的一块拼图
下节课:文本处理基础 — 把原始文字变成机器读懂的数字
课堂讨论
在你的工作场景里:
1. 你手上有哪类文本数据?(问卷 / 报告 / 热线 / 评价 / 其他)
2. 你更想用 LDA 还是词嵌入?为什么?
3. “All models are wrong” — 你觉得模型的哪个输出你最不放心,需要人工把关?
4. 如果给你的工作场景配一个 AI 智能体,它应该能做什么?需要调用哪些工具?
无监督 = 发现隐藏结构
智能体 = 让结构自主行动
LDA 发现话题结构
词嵌入建立语义空间
智能体整合所有 NLP 能力,自主完成复杂任务
All models are wrong, but some are useful.
下节课:文本处理基础 — 把原始文字变成机器读懂的数字