多模态模型
从 CNN 到 VLM:让 AI 同时读懂文字、图像、视频
上节课和期中报告留下的问题
第九课我们把 LLM 当成"会续写文字的概率机器"。期中汇报里,多个同学问到同一类问题——只看文字不够:

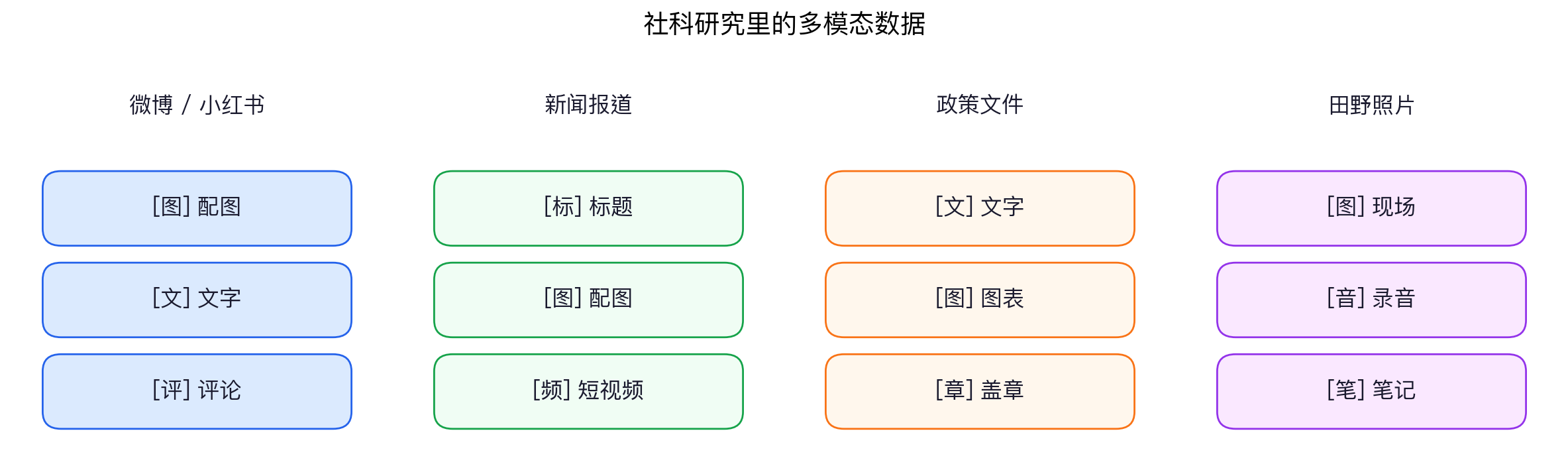
"图文混排,单看文本丢了一半信息"

"5000 张现场照片怎么自动数人头、识别标语?"

"标题 + 配图 + 短视频要联合分析"
今天给一个统一答案:多模态模型——把图像、视频、音频接进 AI。
今天的路线图
大纲标题是"多模态模型"。所以先讲什么是模态、为什么要联合; 传统的 CNN/ViT 视觉线快速过; 重点放在今天的多模态大模型(VLM)——它的架构、能力、主流型号。 最后落到社科应用、可信度验证和伦理边界。
为什么要联合表示
CLIP 打开大门
架构 + 主流型号
验证 + 边界
Part 1 / 4什么是"模态"?为什么要联合?
模态 = 信息的"通道"
过去十年 AI 每个模态各练各的(NLP / CV / ASR)。 多模态模型 = 让一个模型同时读懂多种通道。
为什么社科研究今天必须懂多模态?

Jean et al. 2016 用它预测
非洲村级 GDP(R²≈0.75)
Gebru et al. 2017 用它
推断社区收入与投票倾向
Won et al. 2017 用它
估计暴力程度 + 视觉属性

Williams & Casas 2020
编码海报意识形态信号
多模态的两个核心问题

——它们怎么变成可以比较的东西? © Wikimedia · CC BY-SA
① 表示 Representation
② 对齐 Alignment
后面所有技术(CNN、ViT、CLIP、VLM)都是对这两个问题的不同回答。
Part 2 / 4视觉表示简史:CNN → ViT → CLIP (快速过)
机器"看到"图像的本质
© Wikimedia Commons (CC BY-SA)
模型看到:一个 H × W × 3 的数字矩阵。
每个像素一个 0–255 的 RGB 三元组。
↑ 8×8 的迷你像素阵列。视觉模型干的事—— 把这堆数字压成一个有语义的向量。
文本:word → token → embedding
图像:pixel → patch → embedding
统一后,两类输入都能塞进同一个 Transformer。
CNN:用"卷积核"扫描局部 快速过
分类成
cat / dog / ...
© Wikimedia · CC BY-SA
- 核心:图像有局部性和平移不变性,用小窗口(kernel)扫整张图
- 层级抽象:低层学边缘 → 中层学纹理 → 高层学物体
- 代表:LeNet 1998 → AlexNet 2012 → VGG → ResNet 2015
- 2012 ImageNet:AlexNet 把错误率从 26% 砍到 15%,深度学习破圈
对社科的意义:CNN 第一次让"用图像做测量"成为可行手段。 Naik 2014 用 CNN 给 1.6 万张街景打安全感分数;Gebru 2017 用 CNN 在 5000 万张街景里识别车型,反推社区收入与投票倾向。
局限:每个任务要单独标数据、单独训模型;不会"说话",只输出标签。
ViT:把 Transformer 搬到图像上 快速过
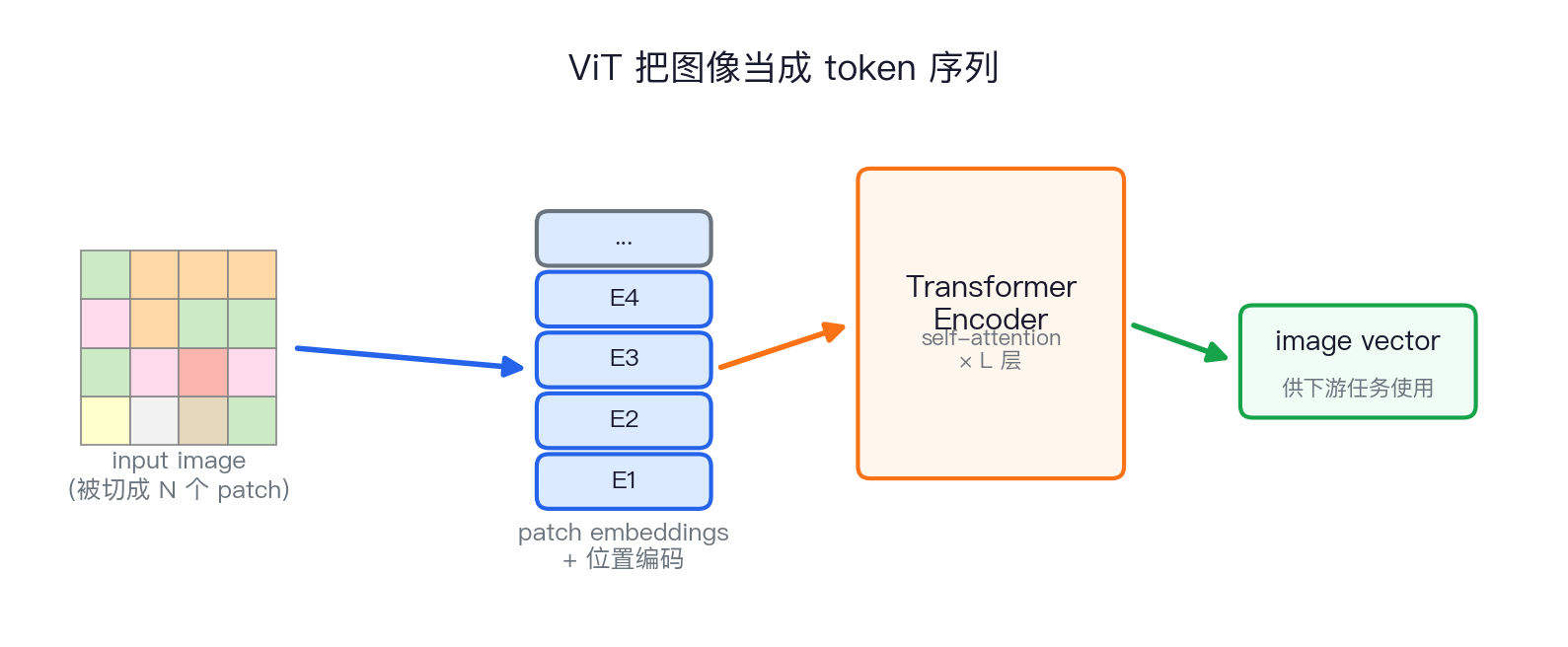
- 把图像切成 16×16 的 patch,每块当作一个 "token"
- 加位置编码,扔进标准 Transformer
- 训练目标和文本 BERT/GPT 几乎一致
- 从此视觉和语言可以用同一种"砖"
今天几乎所有多模态大模型都用 ViT 当视觉编码器。
CLIP:第一次把"图"和"文"真正对齐
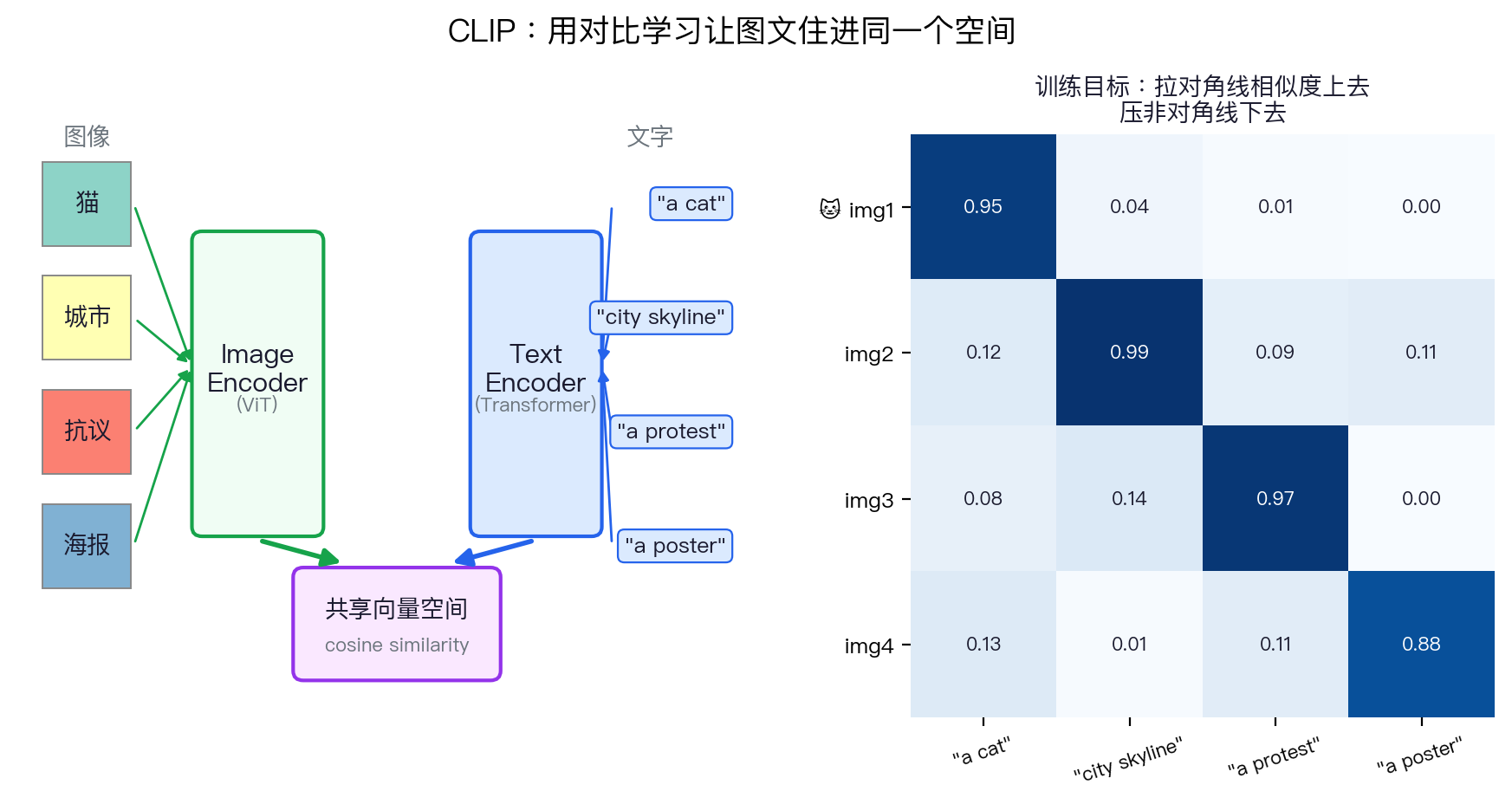
训练完,一句话就能当分类标签——零样本图像分类、检索、过滤、聚类全都解锁。 这是后来 Stable Diffusion、DALL·E、所有 VLM 的技术地基。
本部分小结:三个东西被打通了
Part 3 / 4多模态大模型 VLM (今天的重点)
VLM 是什么?一句话定义
你给它图片 + 文字,它输出文字。
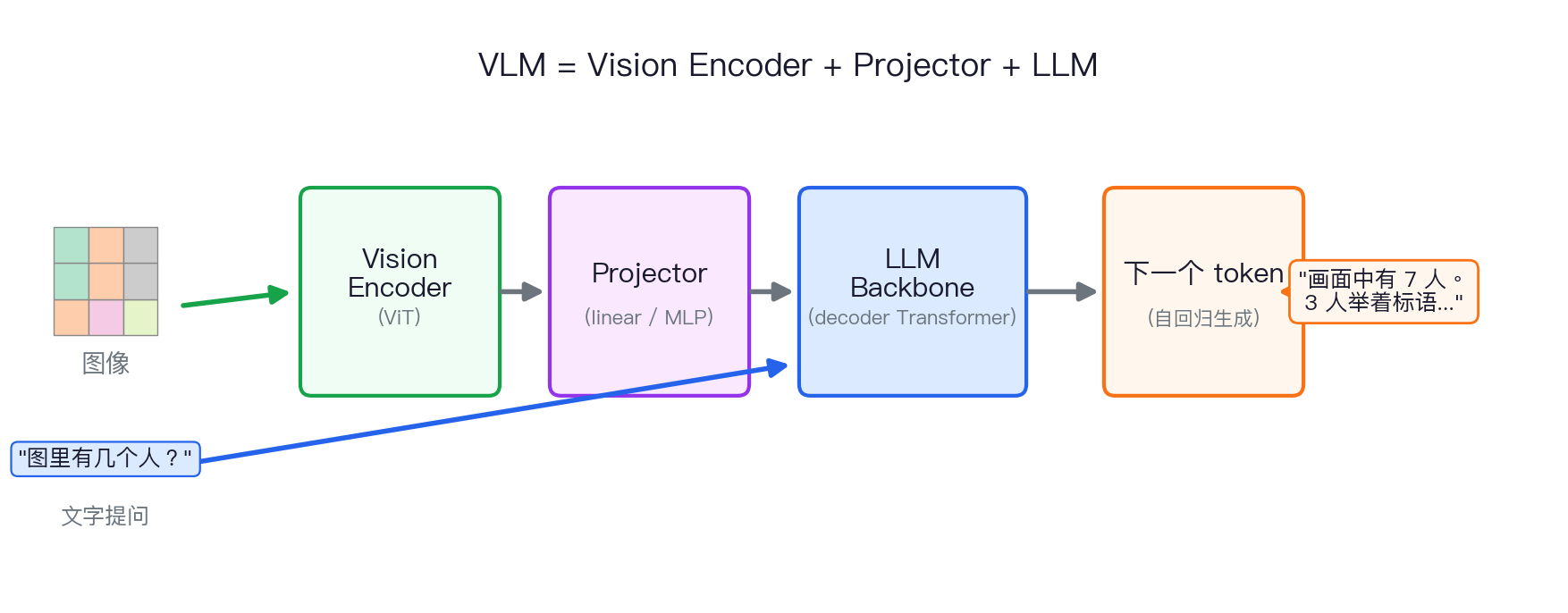
VLM 看到图片之后,内部发生了什么?
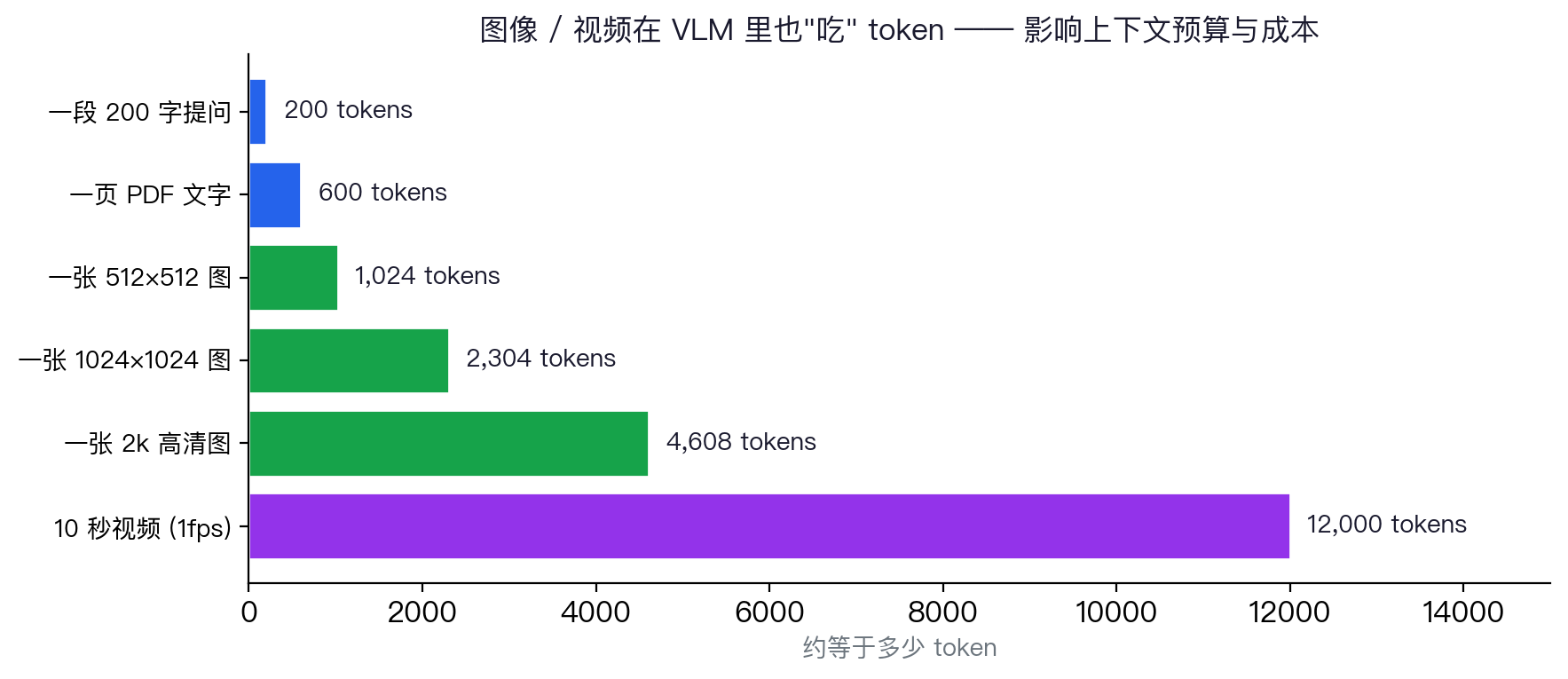
≈ 1024–2304 个视觉 token © Wikimedia · CC BY-SA
- 图像切成 N 个 patch(如 24×24=576)
- ViT 把每块 patch 变成视觉 token
- Projector 投影到 LLM 同维度
- 视觉 token + 文字 token 拼成长序列
- LLM 一路读到底,自回归输出
VLM 看一张真实照片:能做什么
"is_protest": true,
"crowd_size_bucket": "大",
"location_clue": "London, Trafalgar Square",
"signs_visible": true,
"violence_visible": false,
"police_visible": false,
"weather": "overcast",
"main_slogan_en": "STOP ACTA"
}
一张照片 + 一段 prompt → 一份结构化数据。这是社科研究真正受益的地方。
VLM 的能力清单
主流多模态大模型:2026 年课堂选型
| 模型 | 厂商 | 视觉 | 视频 | 音频 | 典型场景 |
|---|---|---|---|---|---|
| GPT-4o / GPT-5 | OpenAI | 原生 | 帧 | 原生 | 通用最强,海报/截图/截屏分析 |
| Claude 4.x / Opus 4.7 | Anthropic | 原生 | 帧 | — | 长文档 + 图表,社科最稳的选择 |
| Gemini 2.5 | 原生 | 原生 | 原生 | 长视频理解、Google Workspace 集成 | |
| Qwen3-VL | 阿里 | 原生 | 帧 | 另一系列 | 中文 OCR、政策文件、本地化 |
| DeepSeek-VL2 | DeepSeek | 原生 | — | — | 开源、可自部署、便宜 |
| InternVL / MiniCPM-V | 书生 / 面壁 | 开源 | 部分 | — | 本地/边缘部署、做实验 |
选型原则:中文场景 → Qwen3-VL / DeepSeek-VL; 需要稳定推理 → Claude; 长视频 → Gemini; 预算紧 → 开源自托管。
VLM 和上一讲讲的 LLM 是什么关系?
第九课的 LLM
输出:文字 token
典型:GPT-4 text, Claude text
Skill 接的就是它
本节课的 VLM
输出:文字 token(绝大多数)
典型:GPT-5, Claude Vision, Qwen3-VL
是 LLM 的超集
所以第九课讲的所有东西都还有效:上下文窗口、幻觉、Skill、Prompt 工程。 VLM 只是多了一个"视觉 token 入口"。今天你不需要重新学一种 AI, 你只需要学会怎么把图片喂给它。
VLM 也会幻觉,而且方式更隐蔽

研究者守则:用 VLM 标注 → 必须随机抽样 → 人工核验 → 报告错误率。 和第九课讲 Agent 时的规矩一样。
Part 4 / 4社科应用:多模态在干什么活
四类典型社科应用
测量贫困、犯罪感、绿化、不平等
Naik 2014 · Jean 2016 · Gebru 2017
人头计数、标语识别、暴力程度
Won 2017 · Sobolev 2020
海报 / 表情包 / 新闻图片视觉框架
Williams & Casas 2020
扫描政策文件、手写问卷、访谈转写
档案数字化(民国报刊、地方志)
案例 1:用卫星图衡量贫困
Jean et al. 2016 (Science):白天图 + 夜光 → CNN transfer learning → 预测非洲五国村级消费/资产水平,R² 达 0.55–0.75。 在调查数据稀缺的地区首次给出大尺度高分辨率社会经济测量。
案例 2:街景图像 → 推断社区构成
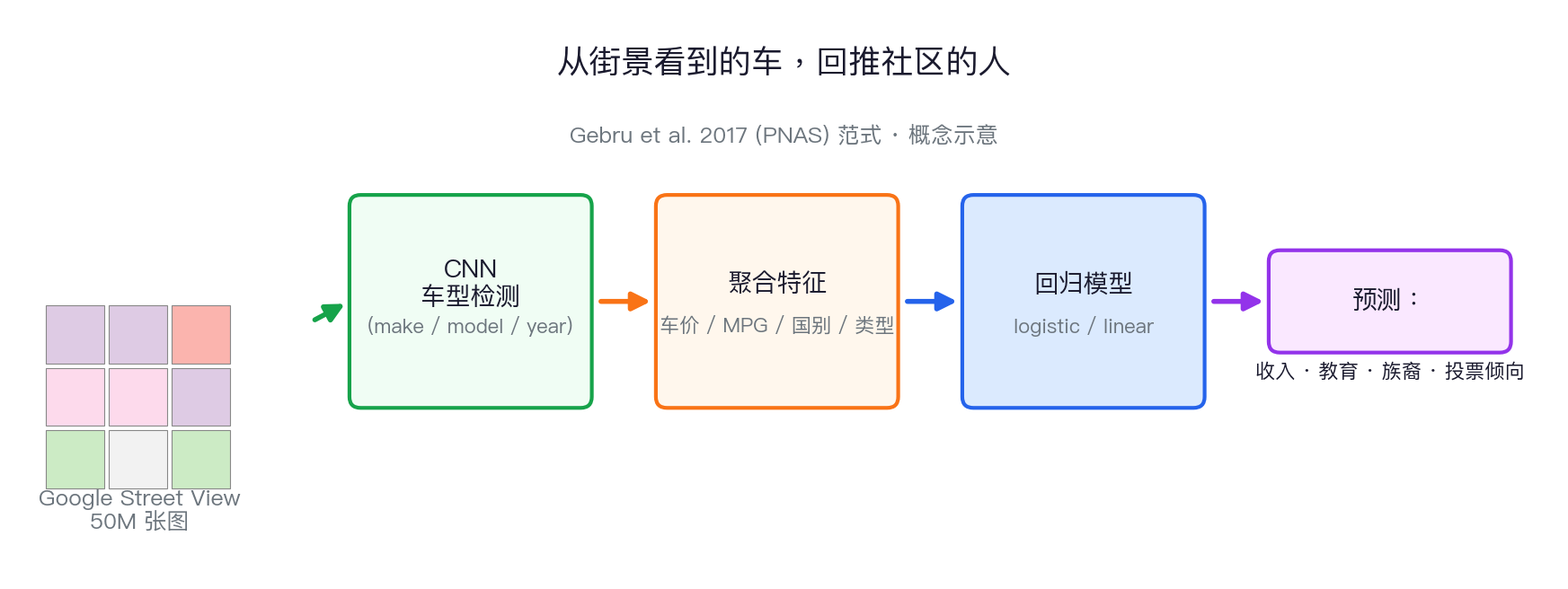
关键发现:城市里 sedan 比 pickup 多 → 88% 概率投民主党;反之 82% 概率投共和党。 用视觉中间变量桥接"图像 → 社会属性",是社科最值得借鉴的设计思路。
案例 3:抗议照片的自动编码
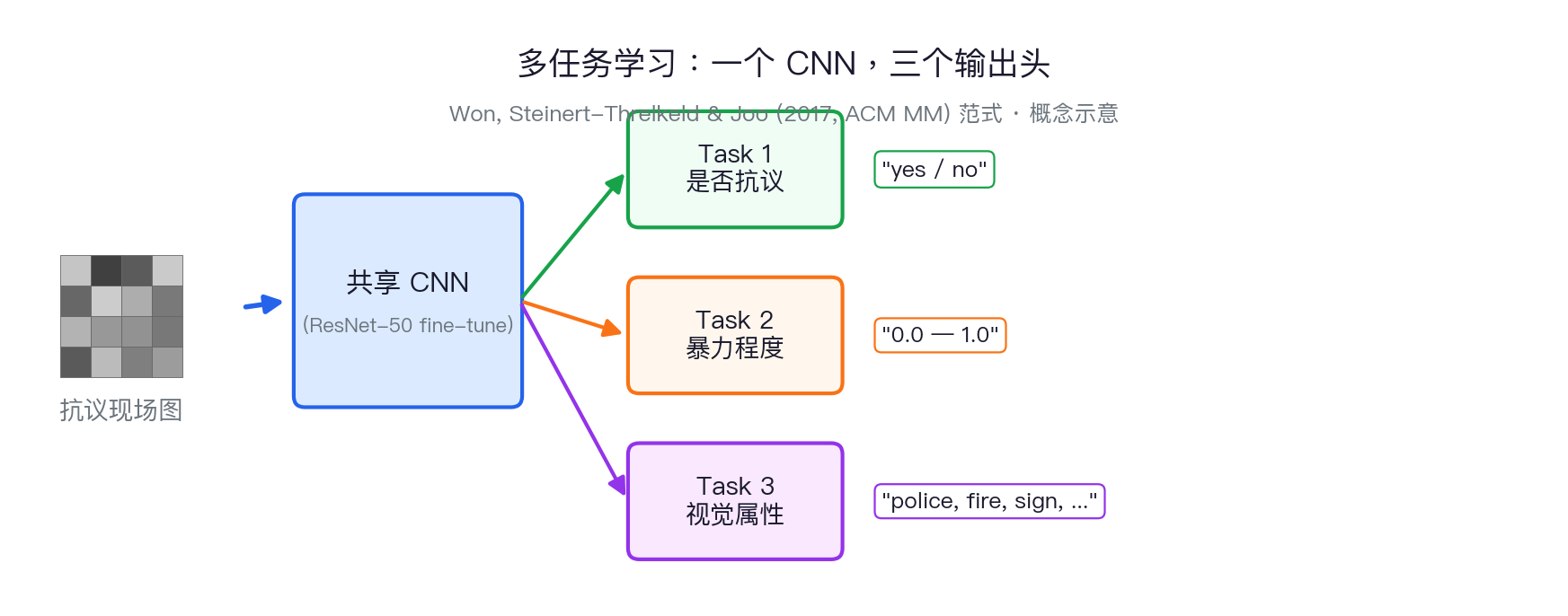
2017 → 2026:从训练多任务 CNN, 变成写一段 prompt 让 VLM 直接输出 JSON。 门槛被推平了——本科生也能做到。
案例:把视频"读"成结构化叙事
典型用例:B 站 / 抖音政治评论视频研究、上访视频、庭审录像、纪录片。 关键 trick:让 VLM逐帧/逐镜头给出客观描述,再让 LLM 把这些描述合成"事件序列"—— 这比"一次性把整段视频塞给 VLM"更可控、更可审计。
论文例子:视觉数据到底能问什么问题?
| 论文 | 视觉数据 | 有趣的问题 | 设计巧思 |
|---|---|---|---|
| Jean et al. 2016 | 卫星图 | 没有调查数据的地方,贫困怎么测? | 先学夜间灯光,再迁移到白天图像 |
| Gebru et al. 2017 | 街景车 | 街上开什么车,能看出社区政治吗? | 把车变成社会经济中间变量 |
| Won et al. 2017 | 抗议照片 | 抗议现场的暴力感怎么大规模测? | 人类先做成对比较,再训练模型 |
| Joo & Steinert-Threlkeld 2022 | 政治图片 | 政治行动者如何被视觉呈现? | 把"图像作为数据"系统化 |
这些论文共同点:它们不是直接问"图片说明了什么",而是先把图片变成可验证的测量对象。
论文例子第一组:城市与发展
白天卫星图 → 贫困预测
有趣点:没有收入调查,也能做高分辨率贫困地图。
街景外观 → 城市安全感
有趣点:城市不是只有人口和收入,街道"长相"也是变量。
街景车辆 → 社区政治倾向
有趣点:sedan / pickup 变成连接生活方式与投票的桥。
论文例子第二组:政治传播与动员
抗议推文配图 → 线上动员
有趣点:图片不是装饰,它会改变传播概率。
新闻候选人照片 → 视觉偏见
有趣点:媒体偏见也藏在脸部大小、表情和构图里。
抗议图片 → 活动/暴力/人群
有趣点:把主观的"暴力感"变成可学习的连续分数。
好玩的例子 1:用街上的车预测政治
这篇最值得学的不是"车能预测投票",而是中间变量设计: 图像本身不能解释政治,但"车辆类型"连接了消费能力、生活方式、城乡结构和政治偏好。
好玩的例子 2:同一个候选人,不同媒体拍出不同脸
15 家新闻网站
13,026 张图片
画面构图、肤色/质感
候选人显著性
也在"选哪张照片"里
Joo et al. 2018 的启发:视觉偏见经常不是显性的立场表达,而是同一事件中反复选择哪种表情、角度和距离。 这类问题,用纯文本很难抓住。
好玩的例子 3:抗议"暴力感"不是二元变量
聪明点:主观概念先交给人做相对判断,再用模型放大,而不是让模型直接定义"暴力"。
好玩的例子 4:VLM 自己也会有政治联想
实验设计
系统改变候选人的视觉人口特征
让 VLM 判断意识形态标签
警示
脸、年龄、性别等视觉线索
可能被错误连到政治标签
Jeon et al. 2026 "From Faces to Politics" 提醒我们:VLM 不只是帮研究者编码偏见, 它自己也可能把视觉人口特征带进政治判断。
好玩的例子 5:一张图片让抗议更容易扩散
讲课时可以问学生:一张抗议图里,什么会触发行动? 人数、愤怒、恐惧、共同身份、警察在场,还是"我也应该去"的可想象性?
好玩的例子 6:城市"看起来安全"会影响什么?
觉得安不安全
扩展到城市尺度
还是阶层偏见?
也能这样测吗?
好玩的例子 7:宣传海报能不能被"读"成政治语法?
| 可编码线索 | 可能连接的理论概念 |
|---|---|
| 人物姿势、视线方向 | 权威、亲近感、动员姿态 |
| 颜色、旗帜、符号 | 国家身份、敌我边界 |
| 口号与字体 | 情绪框架、责任归因 |
| 性别/职业形象 | 公民角色与社会秩序想象 |
这里最适合课堂讨论:VLM 可以先做"低层描述",真正的政治解释仍然要靠理论。
好玩的例子 8:模型错例本身也可以成为发现
如果模型总把某类街区判断为"危险",它是在看治安,还是在复制阶层/种族/城市景观偏见?
如果模型总把某类候选人判断为"激进",它是在读文本,还是在从脸和身份线索做政治联想?
所以多模态研究有两条路:
用模型测量社会,以及
用社会科学审计模型。
第二条路很适合期末项目:拿一组图片,系统比较模型在不同群体、场景、语言提示下的误差。
这些论文教我们的四个设计套路
替代难测概念
变成连续量表
再解释社会意义
当研究对象
一篇好的多模态论文,通常不是"我用了一个更强模型",而是我把一个原来无法规模化测量的社会概念,设计成了可审计的视觉测量。
从案例到研究设计:多模态不是"看图说话"
研究者真正要做的,不是让模型"理解社会",而是把理论概念拆成可以从图像里观察到的线索, 再把这些线索变成可检验的变量。
第一条规则:不要让 VLM 直接替你下结论
| 糟糕问法 | 更好的测量设计 | 为什么 |
|---|---|---|
| 这场抗议激进吗? | 是否有警察、冲突、破坏、火焰、武器 | 把价值判断拆成可见证据 |
| 这个社区富裕吗? | 车辆类型、道路质量、绿化、楼体维护 | 让模型编码中间变量 |
| 这张海报宣传什么意识形态? | 人物、口号、符号、颜色、敌我对象 | 先描述,再解释 |
| 视频里谁对谁错? | 逐镜头记录行动者、动作、时间顺序 | 避免模型编造因果叙事 |
经验法则:VLM 最适合做观察记录员,不适合直接当理论解释者。
编码本怎么写:先定义变量,再让模型执行
| 字段 | 取值 | 人工核验点 |
|---|---|---|
| crowd_size_bucket | 小 / 中 / 大 | 阈值是否一致 |
| police_visible | true / false | 制服、车辆、盾牌 |
| sign_text | 原文摘录 | OCR 是否误读 |
| violence_visible | true / false | 只看画面证据 |
| uncertainty | low / mid / high | 让模型暴露不确定 |
最危险的不是模型不会看,而是它把模糊处说得很确定。 所以编码本里一定要给 unknown / uncertain 留位置。
抽样核验:最小可发表版本
覆盖不同来源与时期
最好双人交叉
相关系数 / 偏差方向
而不是只报一个分数
论文里真正有说服力的是:哪些字段可靠、哪些字段不可靠、误差朝哪个方向偏。 这比一句"我们使用先进 VLM"重要得多。
什么时候值得用 VLM?一个简单判断表
| 低风险 | 中风险 | 高风险 | |
|---|---|---|---|
| 可见事实 | 物体、场景、OCR | 人数区间、动作类别 | 身份、动机、政治立场 |
| 研究用途 | 探索、筛选、辅助检索 | 描述统计、低 stakes 测量 | 因果识别、个体判断、敏感标签 |
| 验证要求 | 少量 spot check | 抽样人工复核 | 双人编码 + 稳健性 + IRB |
| 课堂建议 | 可以放心试 | 可以用,但要报告误差 | 先不要自动化 |
论文方法段必须交代什么
写法目标:让读者能判断这个变量是不是可信,而不是只知道你用了哪个模型。
不用电脑也能做:设计一个多模态测量方案
- 选一个理论概念:动员强度、国家回应、集体身份、情绪氛围
- 拆成 3 个可见变量:每个变量只能依赖画面证据
- 给每个变量写取值范围:true/false、等级、原文摘录、unknown
- 设计人工核验:抽多少、谁来判、错例怎么分类
下课前只交一页纸:变量表 + 核验方案。真正跑模型可以留到课后。
怎样验证 VLM 的编码可不可信?
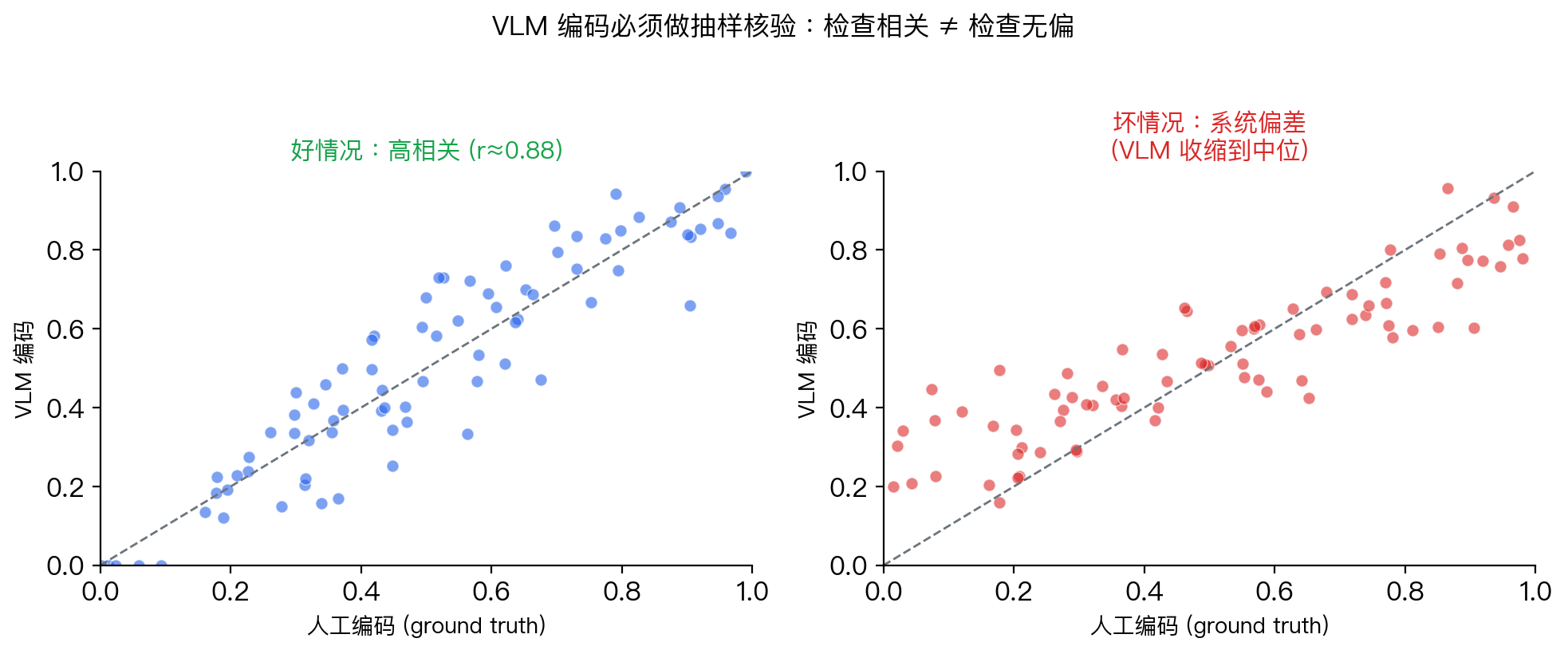
报告时三件事必写:① 抽样规模 ② 相关系数 r ③ 偏差方向(VLM 是否系统性高估或低估)。
多模态的边界:哪些事 VLM 还做不好
✅ 已经很可靠
通用图像描述
简单图表读数
粗粒度场景分类
提取明显物体属性
⚠️ 仍不可全信
细粒度文化语义(地域、政治符号)
手写体、潦草字体
长视频中的因果叙事
细节空间关系(谁在谁左边)
研究者的责任:把 VLM 当成高速但偶尔糊涂的研究助理。 可以让它处理 10 万张图;但你必须设计一套抽样核验机制,再写进论文方法论里。
伦理与合规:多模态特有的风险

课堂讨论
带着你自己的研究问题:
1. 你的研究数据里有多少模态被你忽略了?为什么?
2. 如果用 VLM 给图像编码,哪个变量你最不放心?怎么验证?
3. 多模态把测量变便宜了——这会改变你的研究问题选择吗?
4. 不开电脑也能先做:为一张研究图片写出变量、JSON schema 和抽样核验方案
定义 3 个变量
写清楚人工核验规则
是计数、语义
还是文化语境?
VLM 在你的数据上
能做 / 不能做什么
多模态不是新 AI
是同一个 LLM
多了一双眼睛
第九课 LLM 的全部规则都还在:上下文、幻觉、Skill、Prompt。
多模态只是让你的原始数据第一次能被算法直接读懂。
过去靠人工编码图像与视频的研究,现在可以放大百倍——前提是你为它设计验证机制。
Seeing is still believing — but verify the model is seeing. 郑思尧 2026