社交媒体分析
与多智能体
从平台数据到群体智能研究流水线
上节课留下的问题
但模型“看懂了”不等于研究问题被回答了。
你需要的不只是一个模型,而是一套可复核的研究流水线。
今天的路线图
先看原文图:社交媒体数据长什么样
图源:Pan, Xu & Jiang, AJPS 2025;Barberá et al., APSR 2019 及 online appendix;Waller & Anderson, Nature Human Behaviour 2023 及 supplementary information。
Part 1 / 4社交媒体不是“一堆文本”
案例一:抖音政务账号的“去中心化传播”
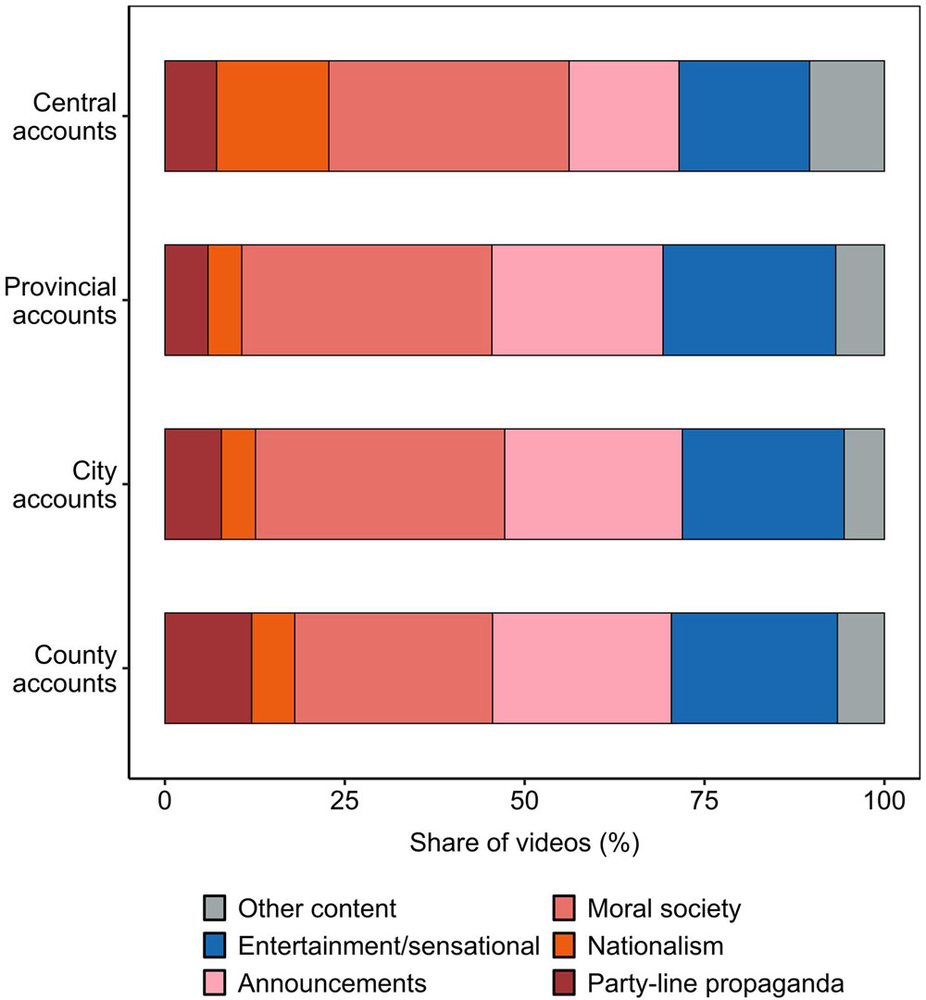
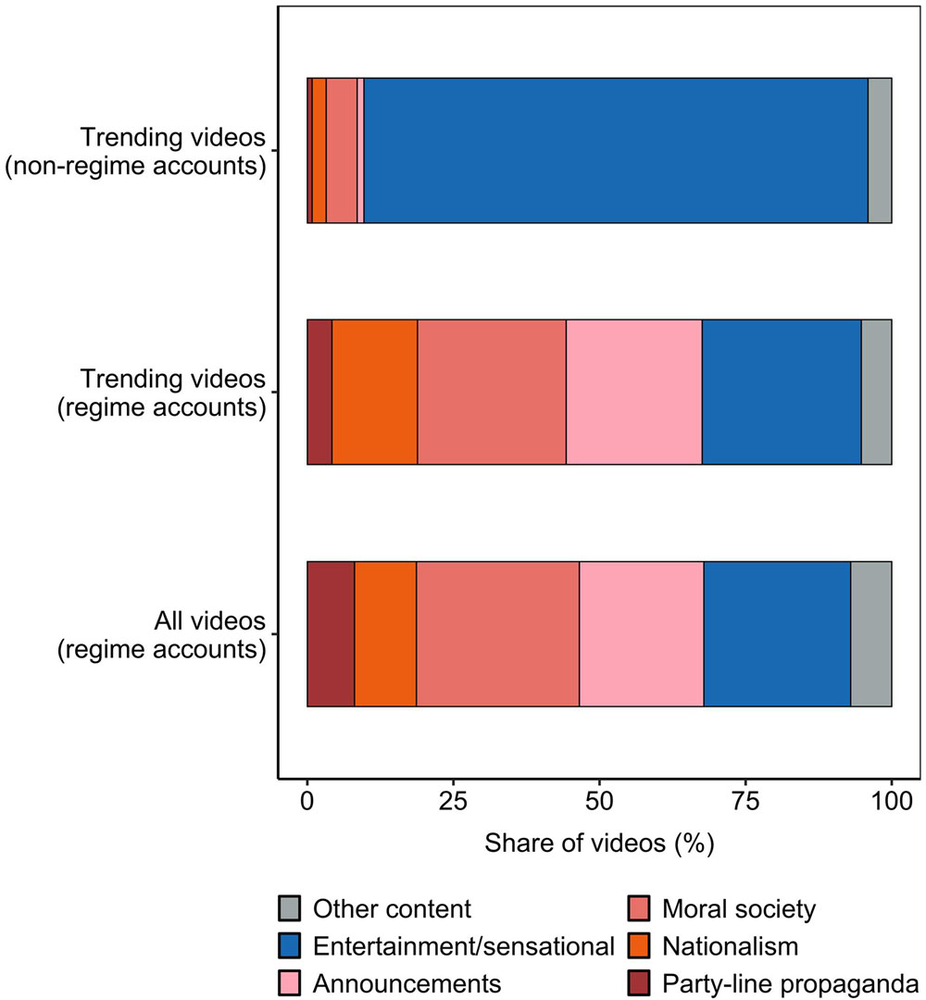
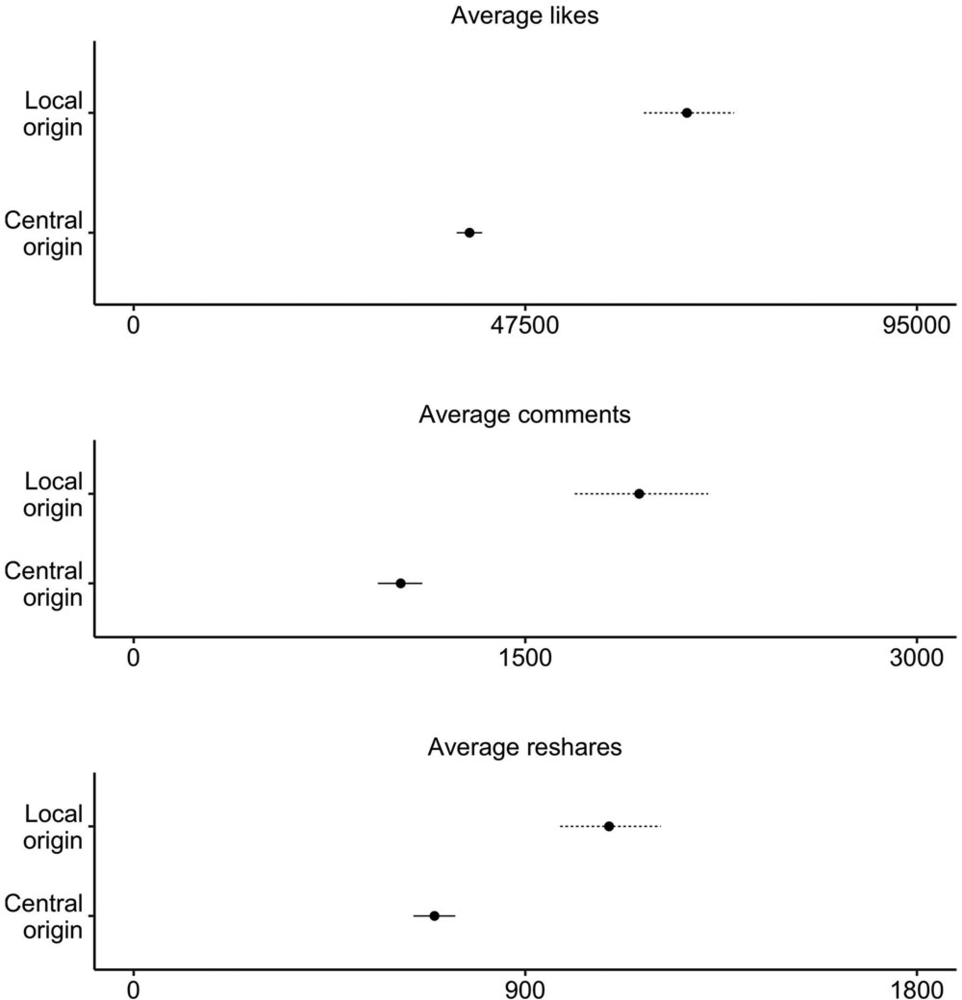
这一组图的教学点:同一平台研究同时需要时间、账号、内容、传播方向和互动结果。
同一条帖子,同时是很多东西
社交媒体对象图
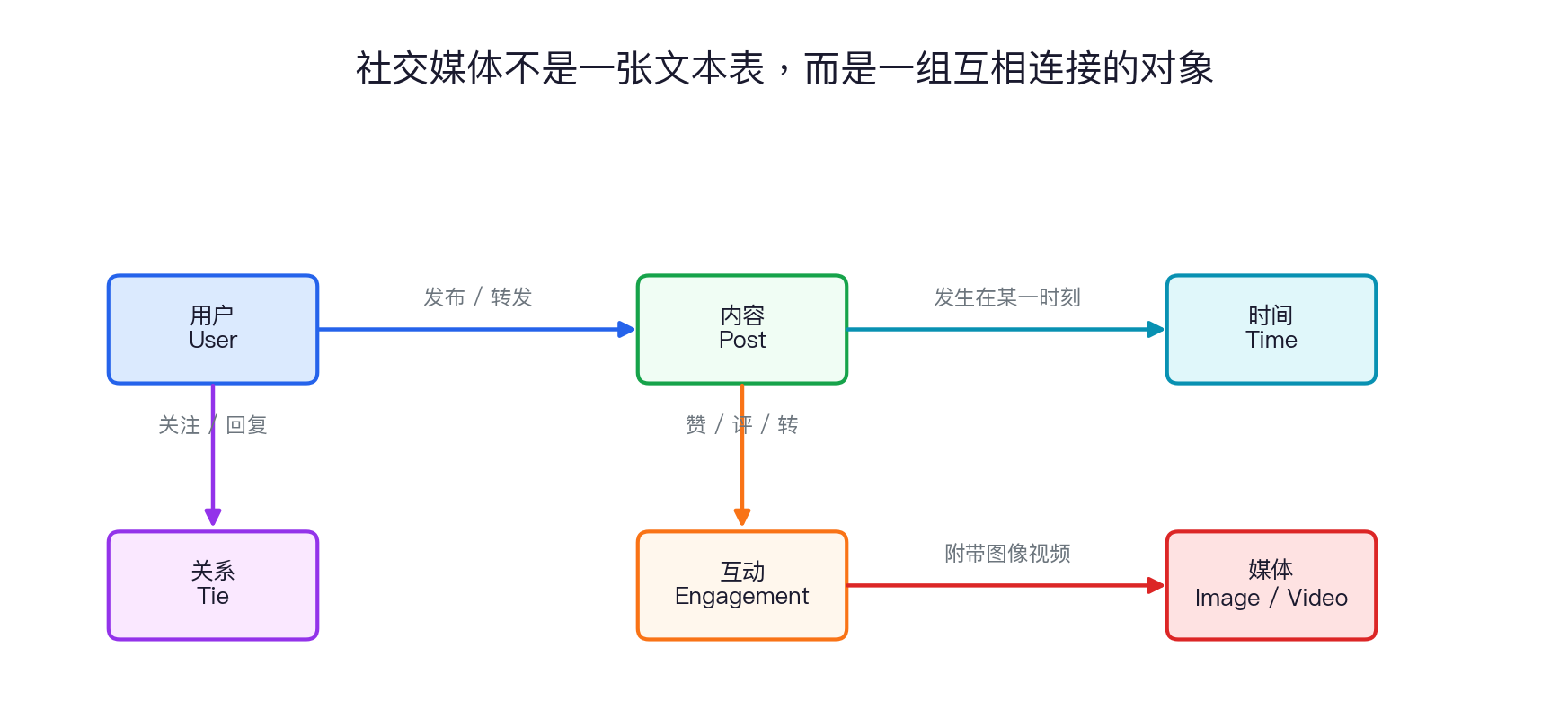
原文图:同一个“帖子”背后是生产网络
讲授点:内容类别、行政层级和转发方向一起定义传播机制;不能把视频只当作一段文本。
平台痕迹不是社会本身
平台痕迹是行动留下的记录。
它来自平台设计:什么能被看见、什么能被转发、什么能被搜索、什么会被删除。
- 评论多,可能是争议,也可能是平台推送。
- 点赞少,可能是没人认同,也可能是人们不愿公开表态。
- 热搜上榜,可能是社会关注,也可能是平台运营。
- 话题消失,可能是兴趣衰减,也可能是可见性改变。
先把研究对象说清楚
| 你想研究什么 | 平台上能看到什么 | 可能的变量 | 最容易错在哪里 |
|---|---|---|---|
| 公众情绪 | 帖子和评论里的表达 | 情绪方向、强度、对象 | 沉默者不可见,讽刺难识别 |
| 议题扩散 | 转发链、话题标签、时间序列 | 扩散速度、桥接节点、峰值时间 | 推荐机制与真实传播混在一起 |
| 身份动员 | 头像、简介、标签、语言风格 | 身份线索、群体边界、行动号召 | 把表演性身份当成稳定属性 |
| 政策反馈 | 政策文本下的评论与二次传播 | 支持/反对、诉求类型、理由结构 | 平台用户不代表政策受众总体 |
操作化:从社会现象到可检查变量
关键原则:不要从“我抓到了什么字段”开始,而要从“我想解释什么机制”开始。
Part 2 / 4平台数据的偏差与边界
从社会到样本:每一步都在漏
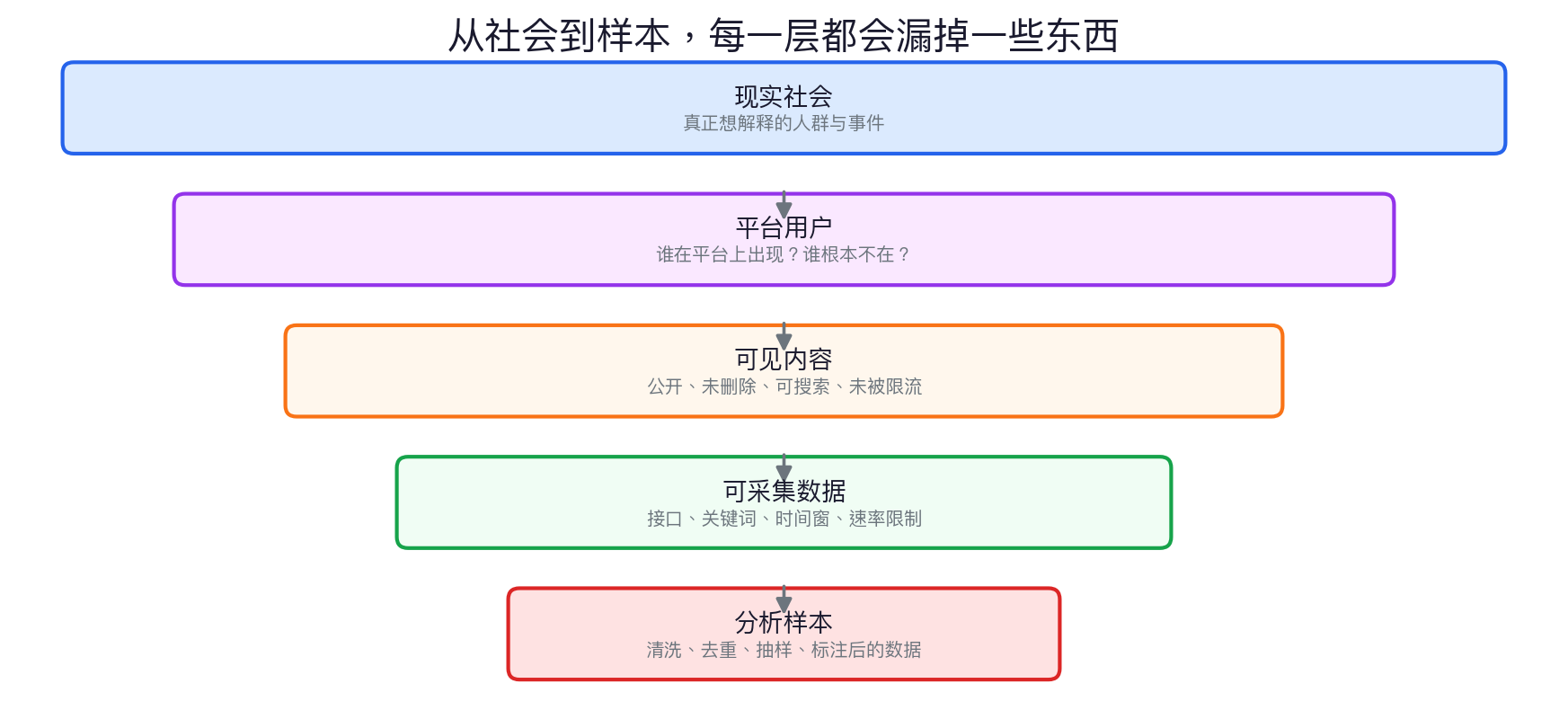
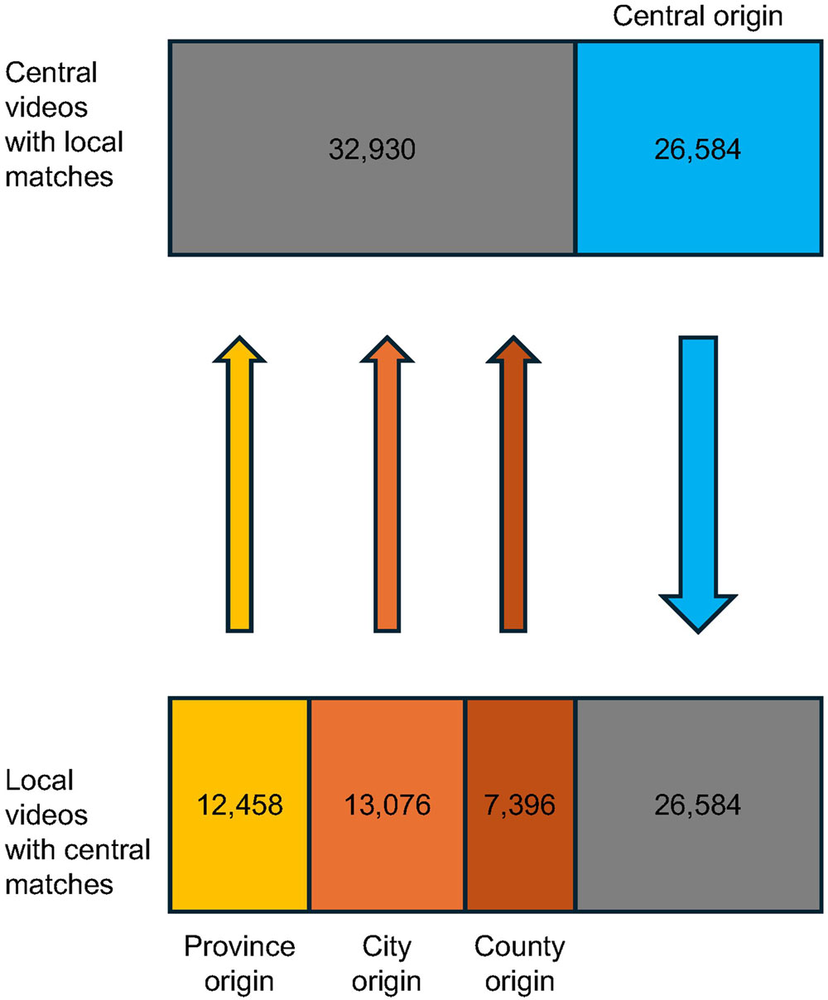
Appendix 也要看:样本是怎样被筛出来的

这张图比方法段更直观。
它把随机用户样本、账号判定、语言过滤、平台约束和人工检查串成一个可复核流程。
- 样本框不是“Twitter 用户”,而是被一系列规则筛过的用户。
- appendix 图能帮助读者发现论文主文里看不到的排除路径。
图源:Barberá et al., APSR online appendix, Figure A1。
四类常见偏差
“大数据”也可能只是很大的方便样本
采集日志是研究的一部分
| 必须记录 | 为什么重要 | 报告时怎么写 |
|---|---|---|
| 平台、入口、关键词、时间窗 | 定义样本框 | “我们采集的是可搜索的公开内容,不是全平台总体。” |
| 失败请求、缺失字段、限速 | 判断数据是否系统性缺失 | “高峰期接口失败率较高,传播峰值可能被低估。” |
| 清洗规则与删除数量 | 避免事后调参 | “去重后删除 18%,主要来自同账号重复转发。” |
| 人工检查样本 | 发现模型和规则的盲区 | “抽检显示讽刺表达是主要误判来源。” |
伦理边界:公开不等于随便用
课堂原则:只用公开、低风险、教学用样例;正式研究要走伦理审查和数据治理流程。
Part 3 / 4内容、网络与时间:三种信号
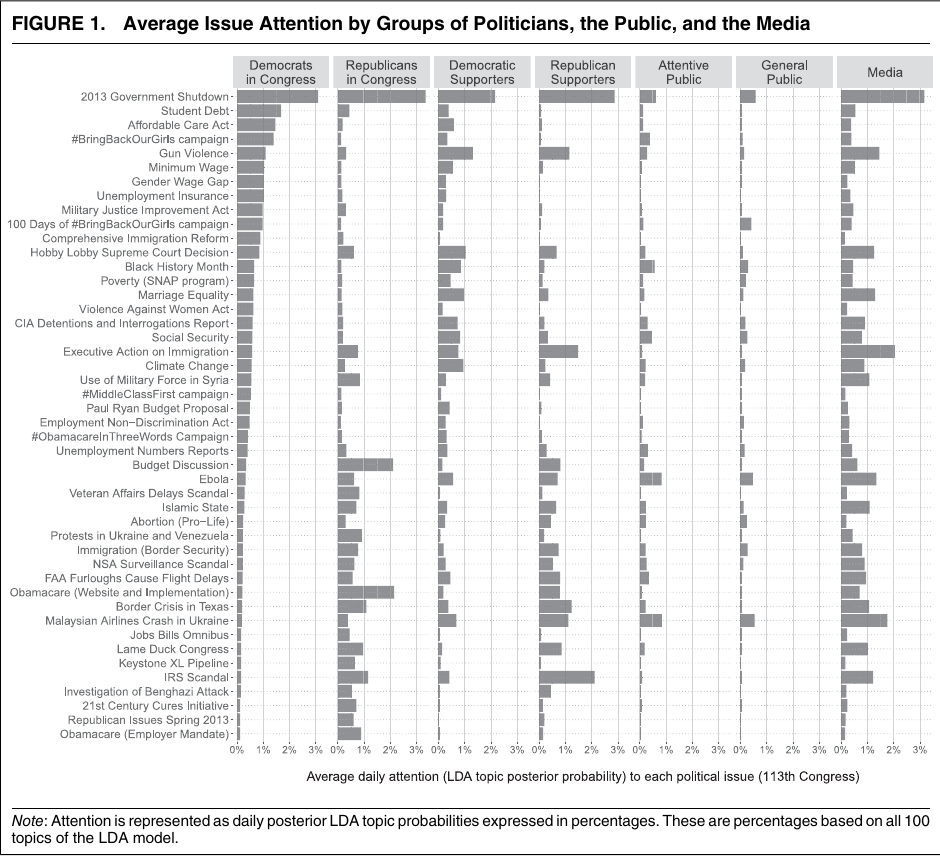
案例二:议题注意力,不只是“谁发得多”
这张图先把不同群体的议题注意力摊开:同一议题在议员、支持者、一般公众和媒体之间的权重不同。
原文图:谁先动,谁跟随
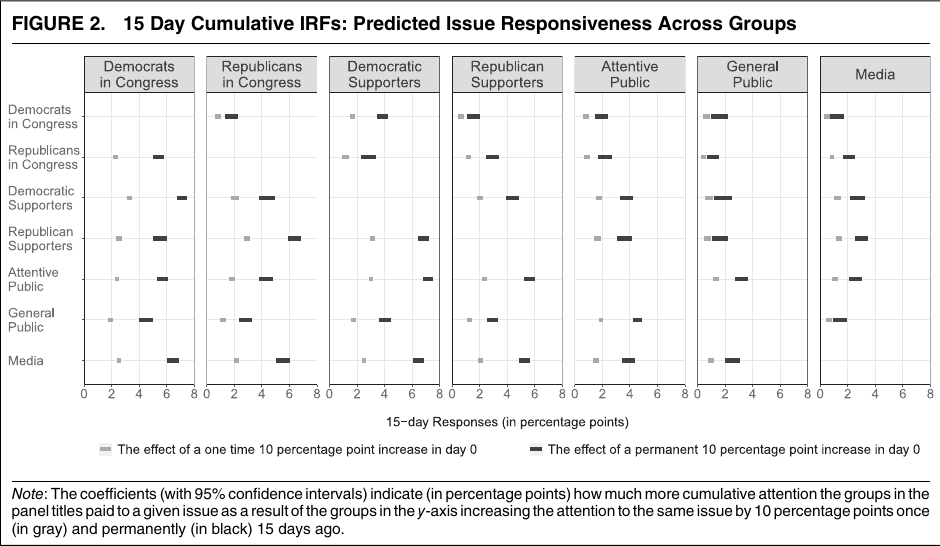
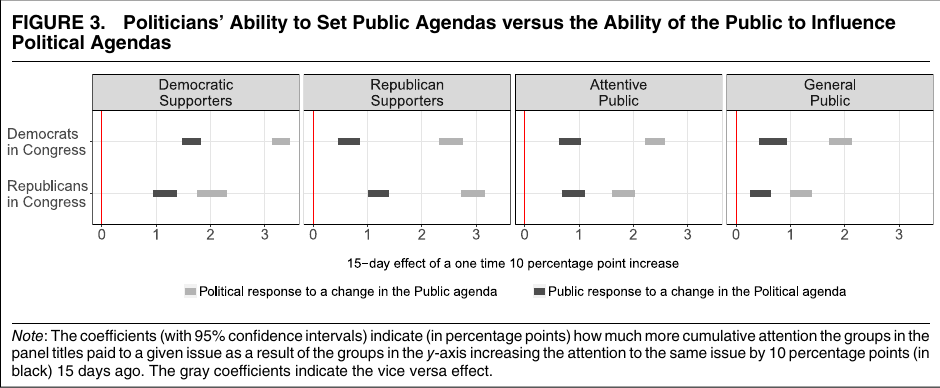
图源:Barberá et al., APSR 2019, Figures 2-3。
原文图:机制可以分解到具体议题
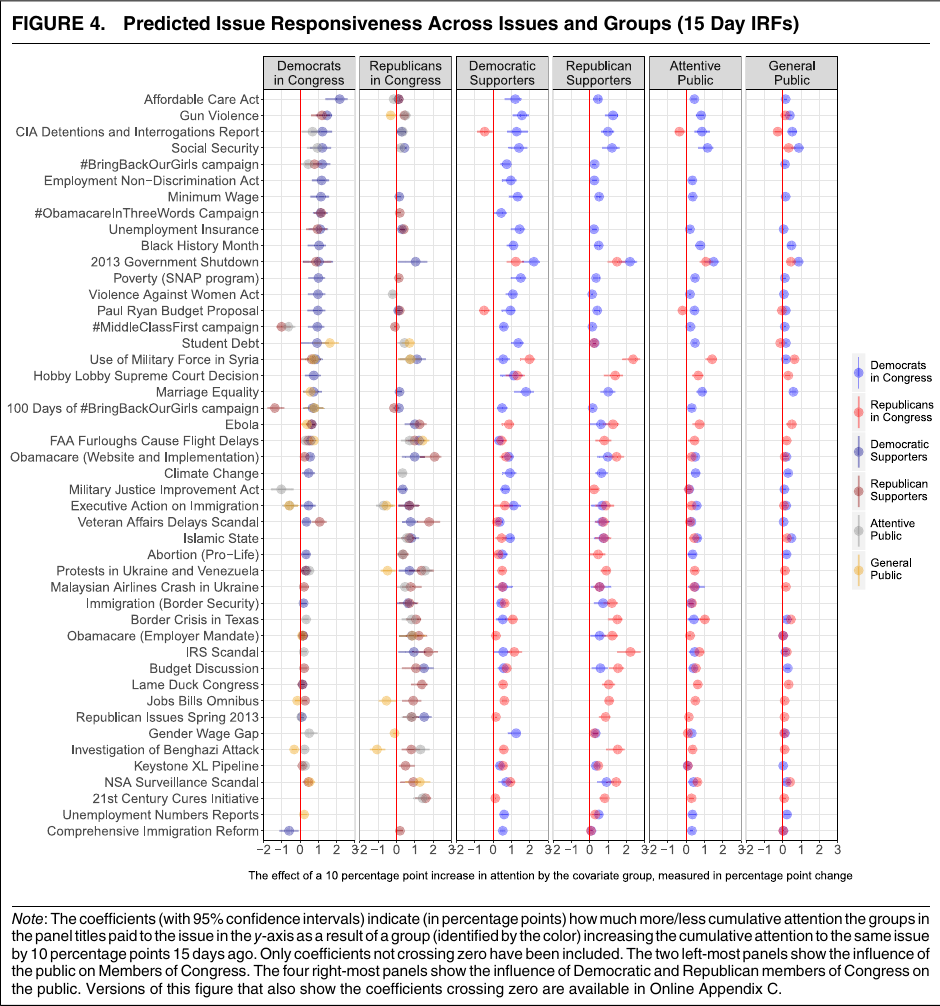
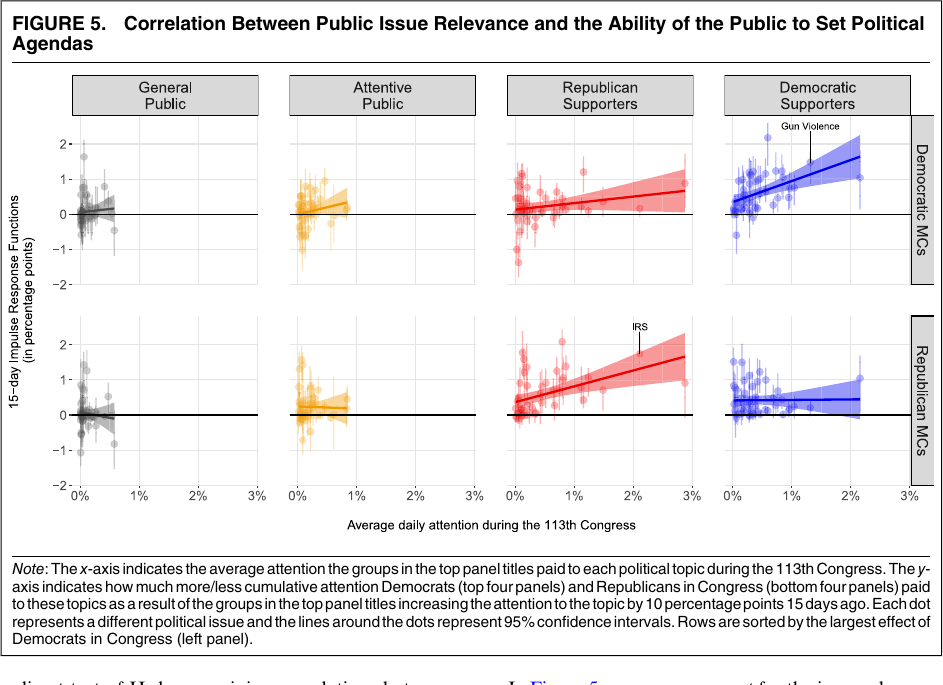
讲授点:先用总体模型回答“谁影响谁”,再回到议题层面解释“在哪些议题上更明显”。
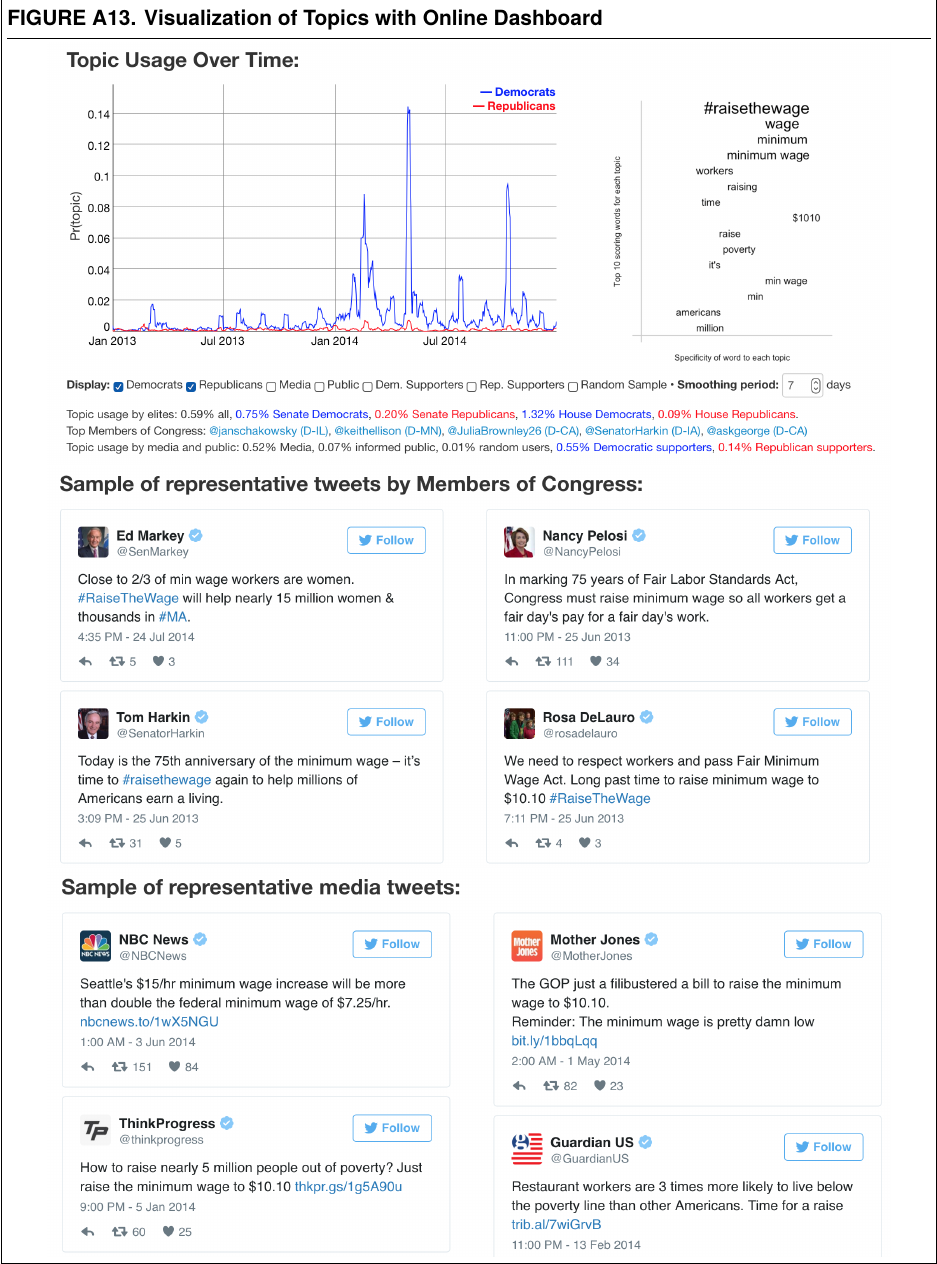
Appendix 的价值:topic 要能回到原帖
这不是“多一张好看的图”。
它把 topic usage over time、关键词、代表性 tweets 和媒体样本放在一起,让主题模型的解释可被检查。
- 模型输出必须能回到具体文本。
- appendix 可以承担透明性和复核性。
图源:Barberá et al., APSR online appendix, Figure A13。
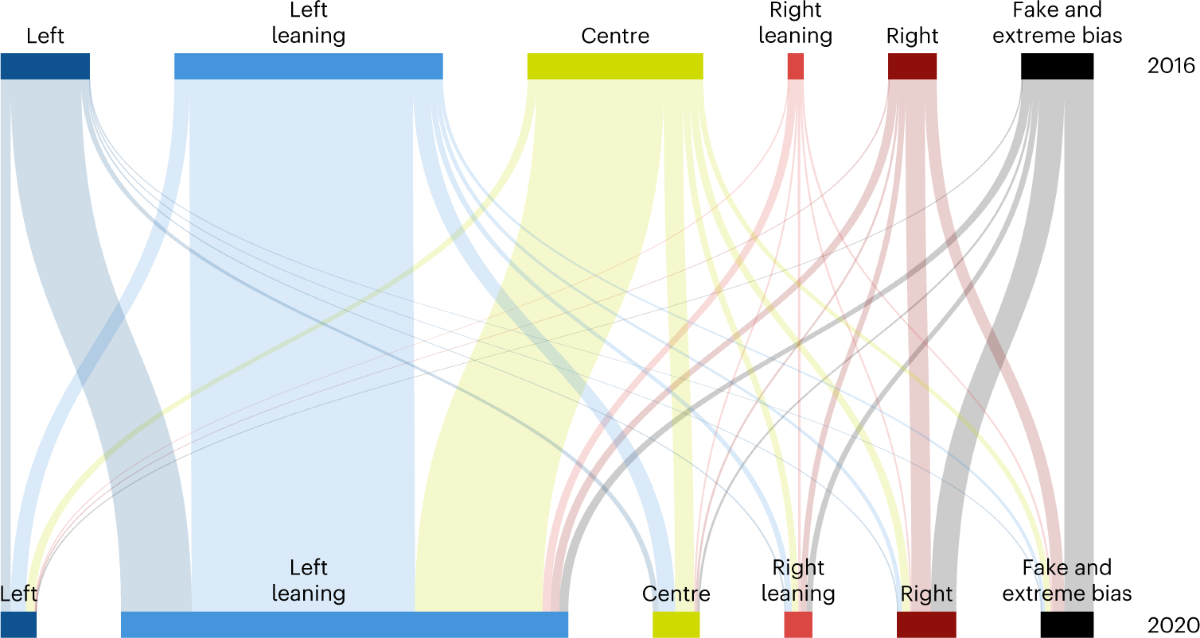
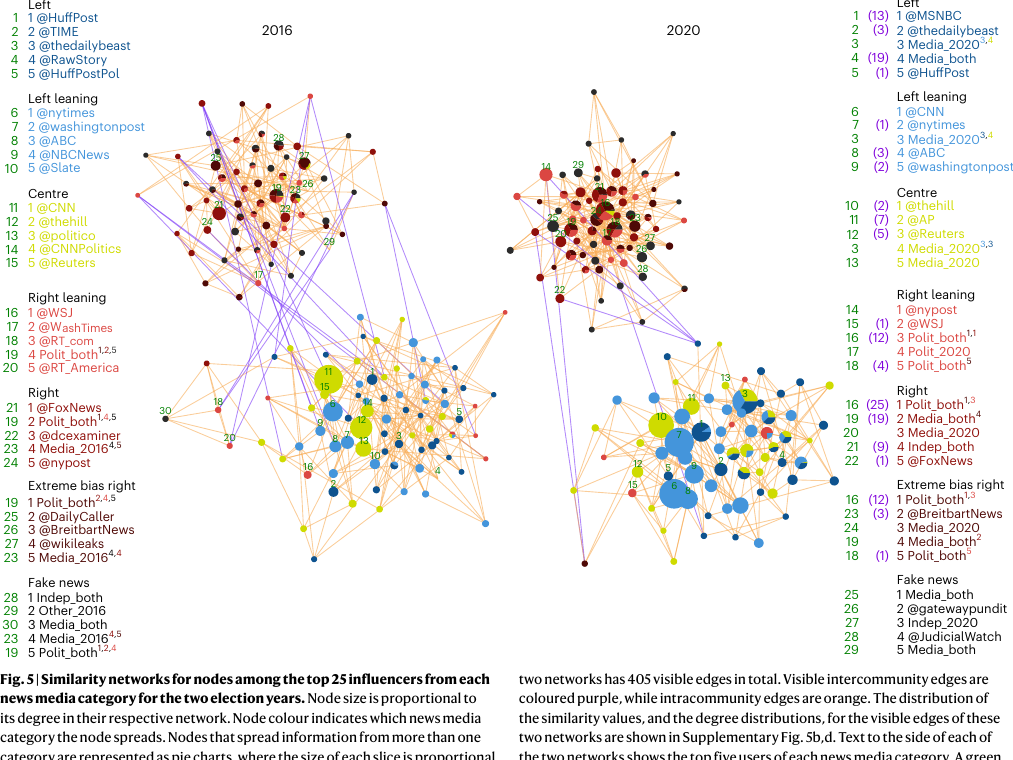
案例三:影响者、新闻链接与极化
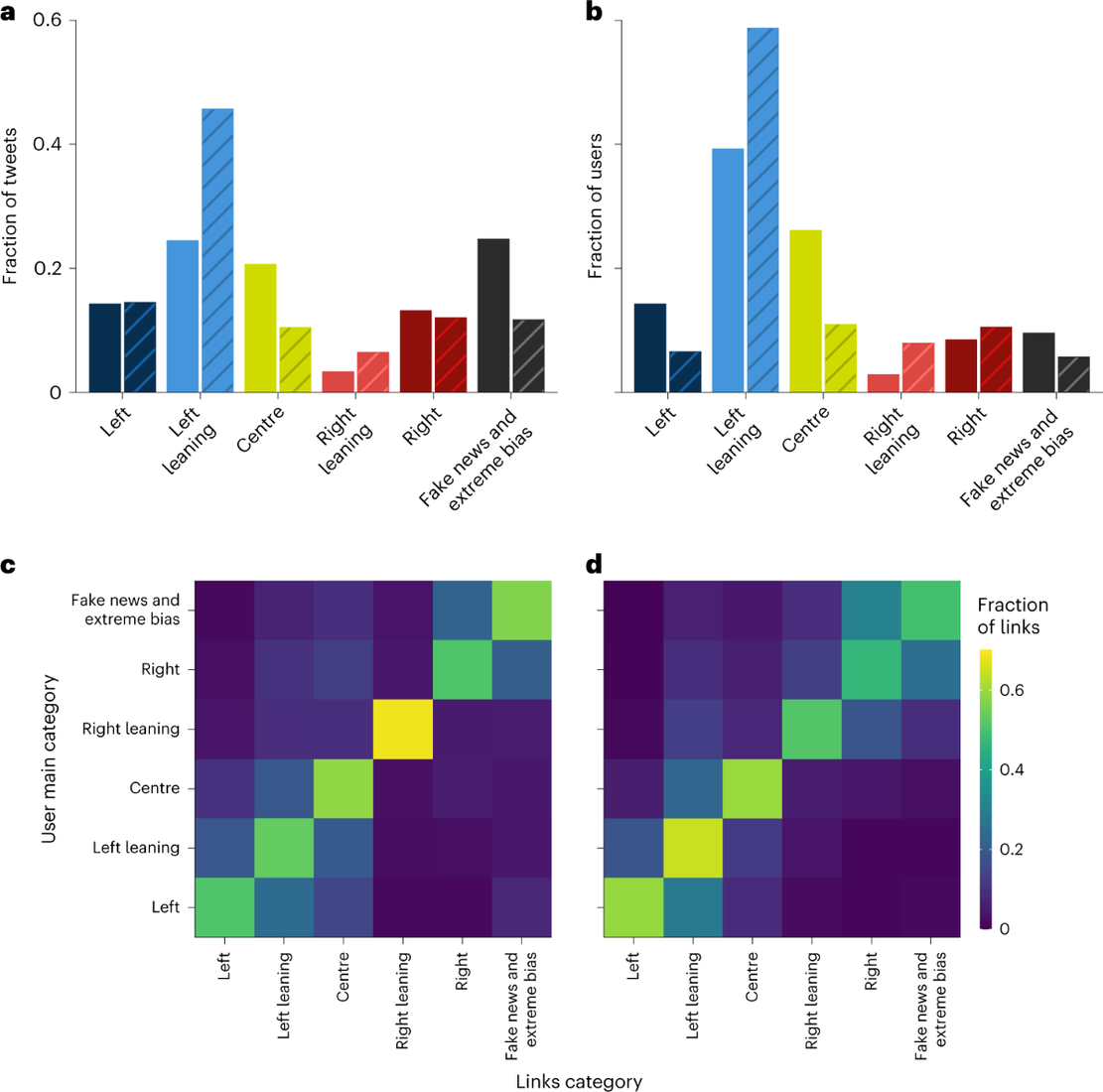
图源:Waller & Anderson, Nature Human Behaviour 2023, Figures 1-2。
原文图:网络结构本身就是发现
同一批 top influencers 的 retweeter similarity network 从 2016 到 2020 更分裂;这比只报告一个极化指数更容易让学生看懂机制。
原文图:从网络再回到潜在意识形态
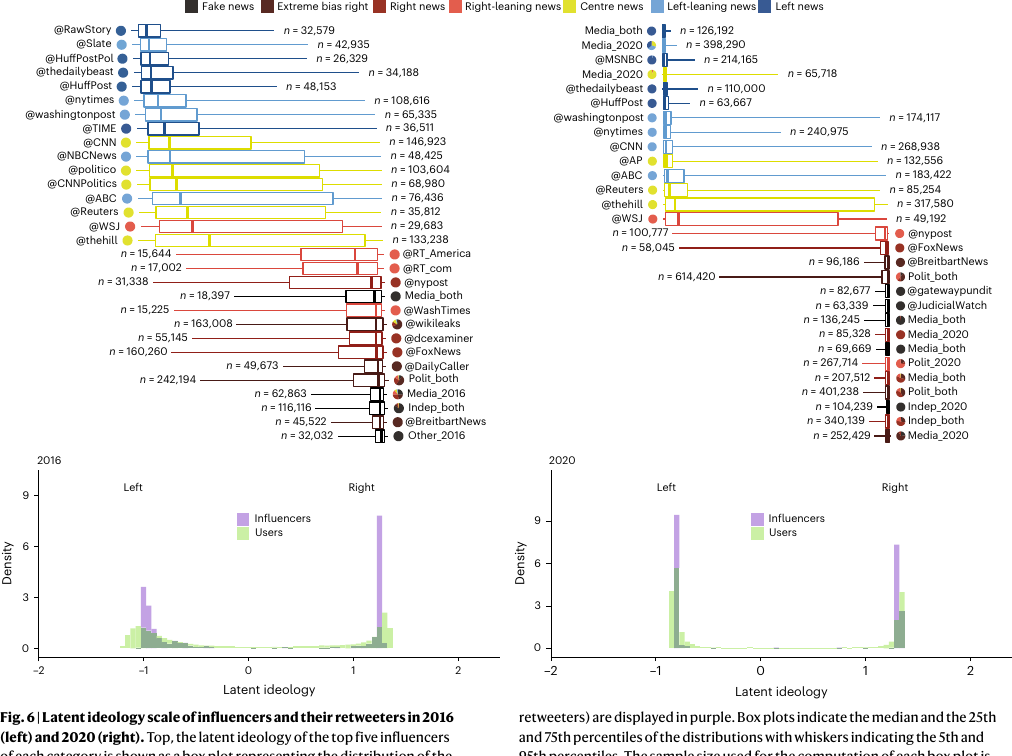
图源:Waller & Anderson, Nature Human Behaviour 2023, Figure 6。注意这里不是情绪分类,而是用转发关系估计潜在位置。
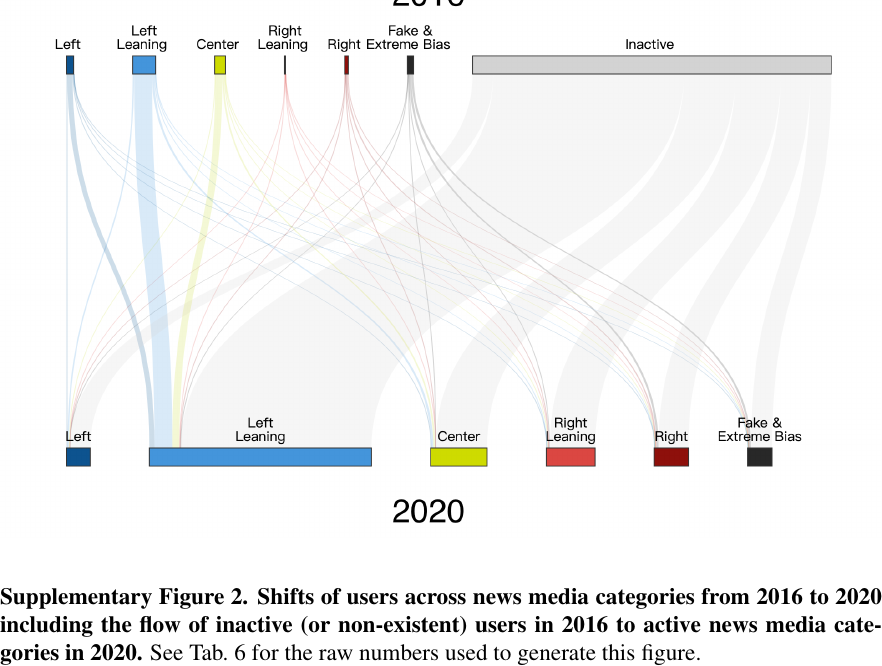
Supplementary figures:样本流失也是机制线索
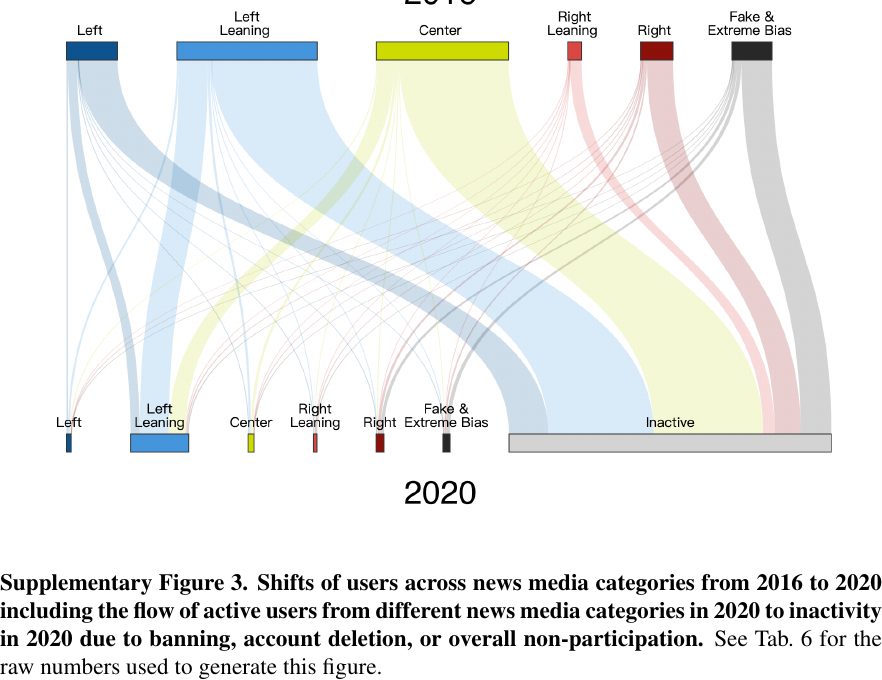
讲授点:appendix 不只是“备份结果”,也可能包含理解数据生成过程的关键图。
内容分析:帖子在说什么
不要只问:这条帖子是正面还是负面?
更好的问法:它把责任归给谁?调用了什么身份?提出了什么行动?它和图像是否互相强化?
从热搜标题转向微趋势
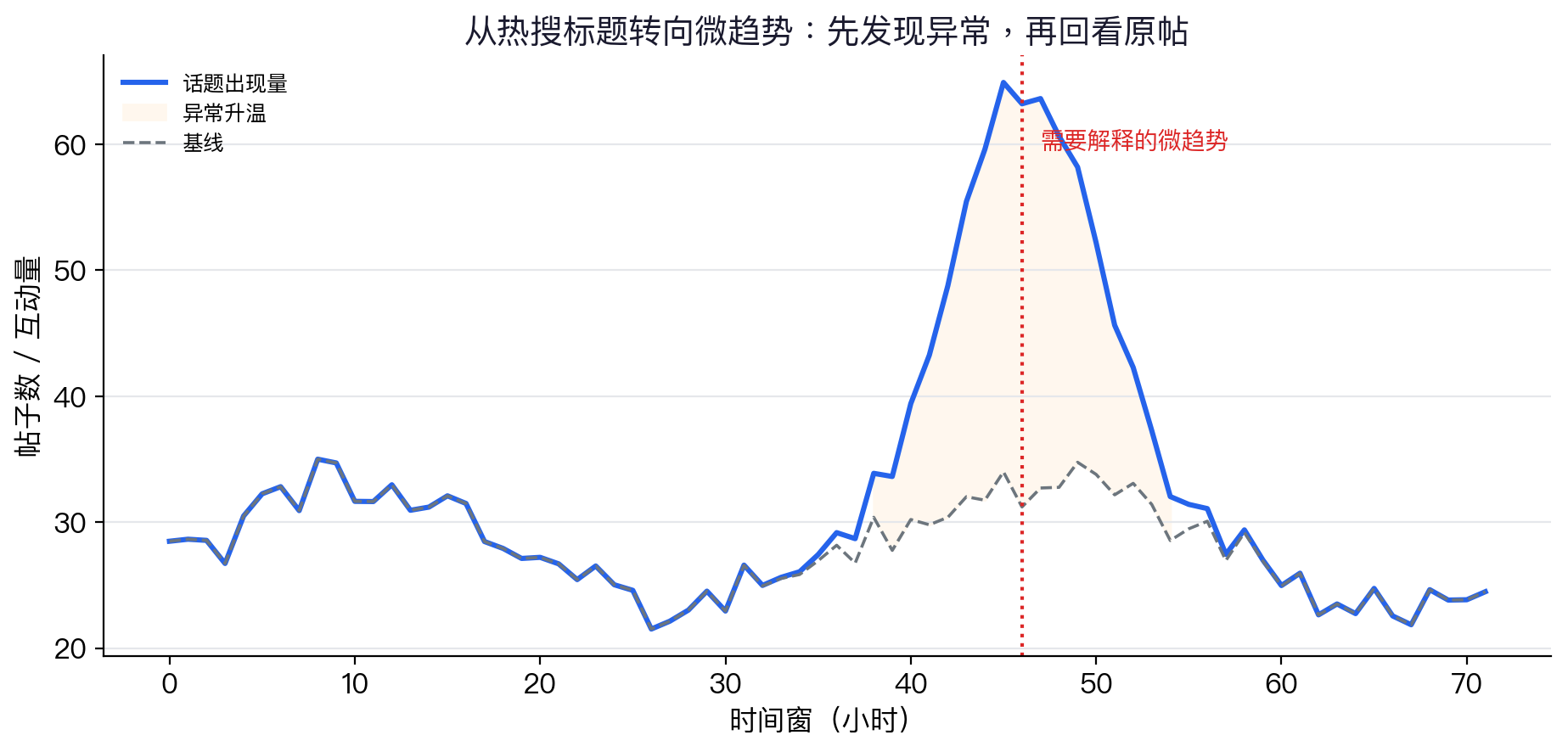
微趋势分析的重点不是“这个话题火了”,而是“为什么在这个时间窗、这个群体、这个表达方式突然变多”。
网络分析:谁连接了谁
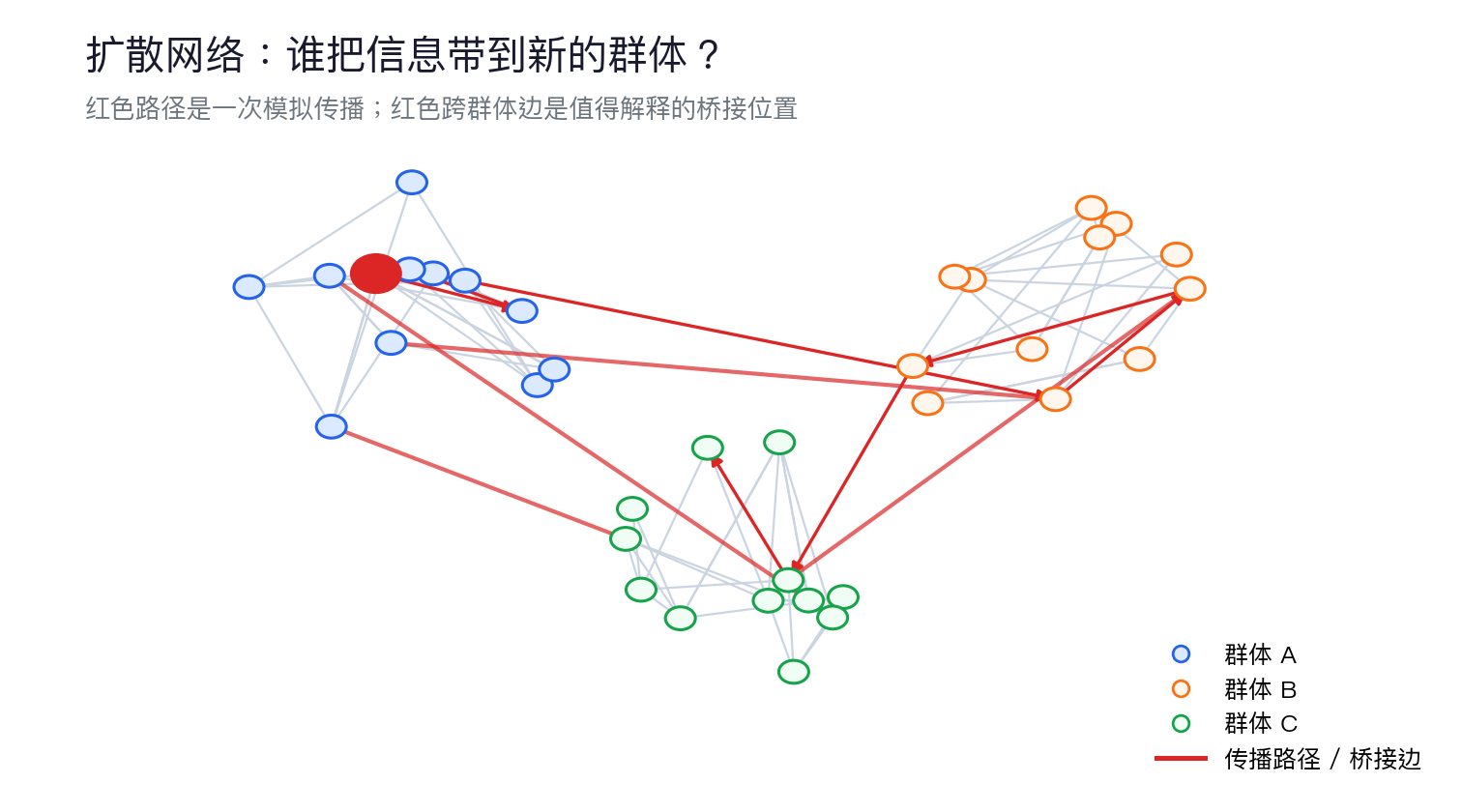
时间分析:什么时候发生
时间序列不要只画曲线。要把平台事件、线下事件、媒体报道、政策节点一起放进解释框架。
多模态社交媒体:第十一讲接到这里
社交媒体的“意义”经常在这些模态之间,而不是某一个字段里。
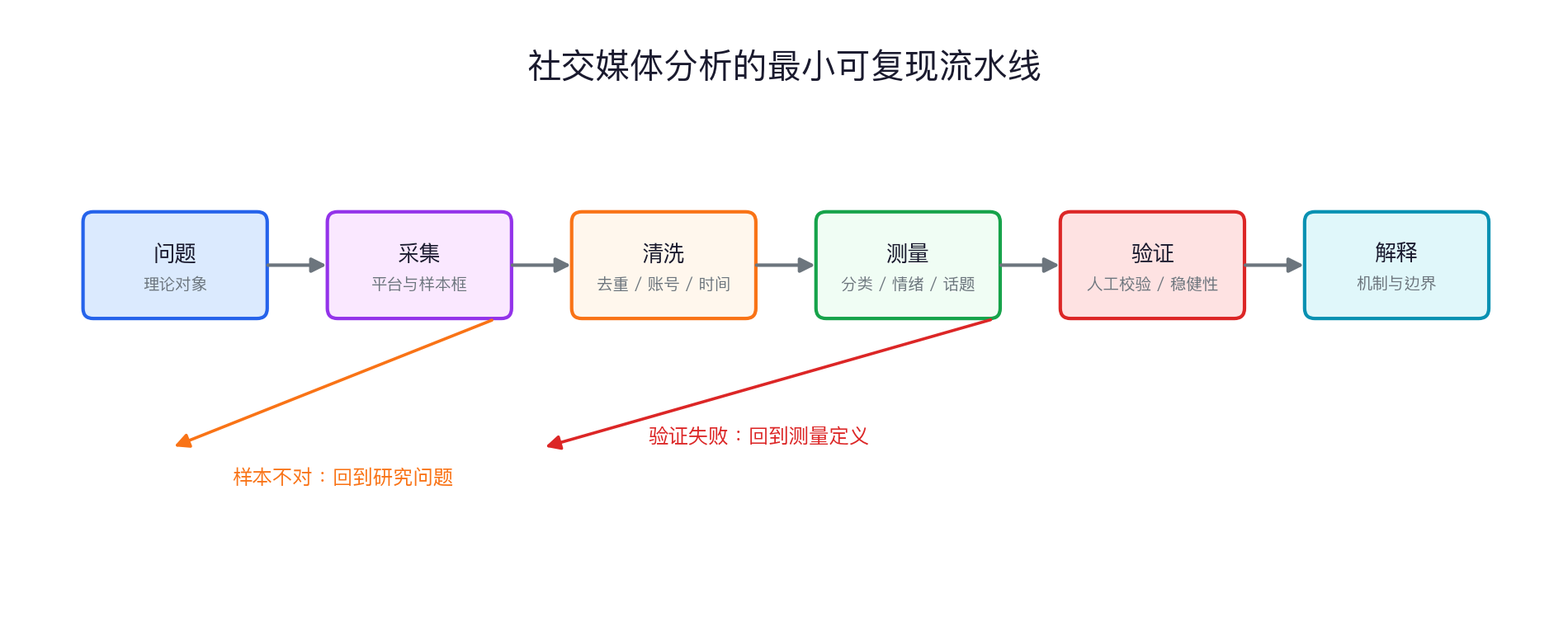
分析流水线:最小可复现版本
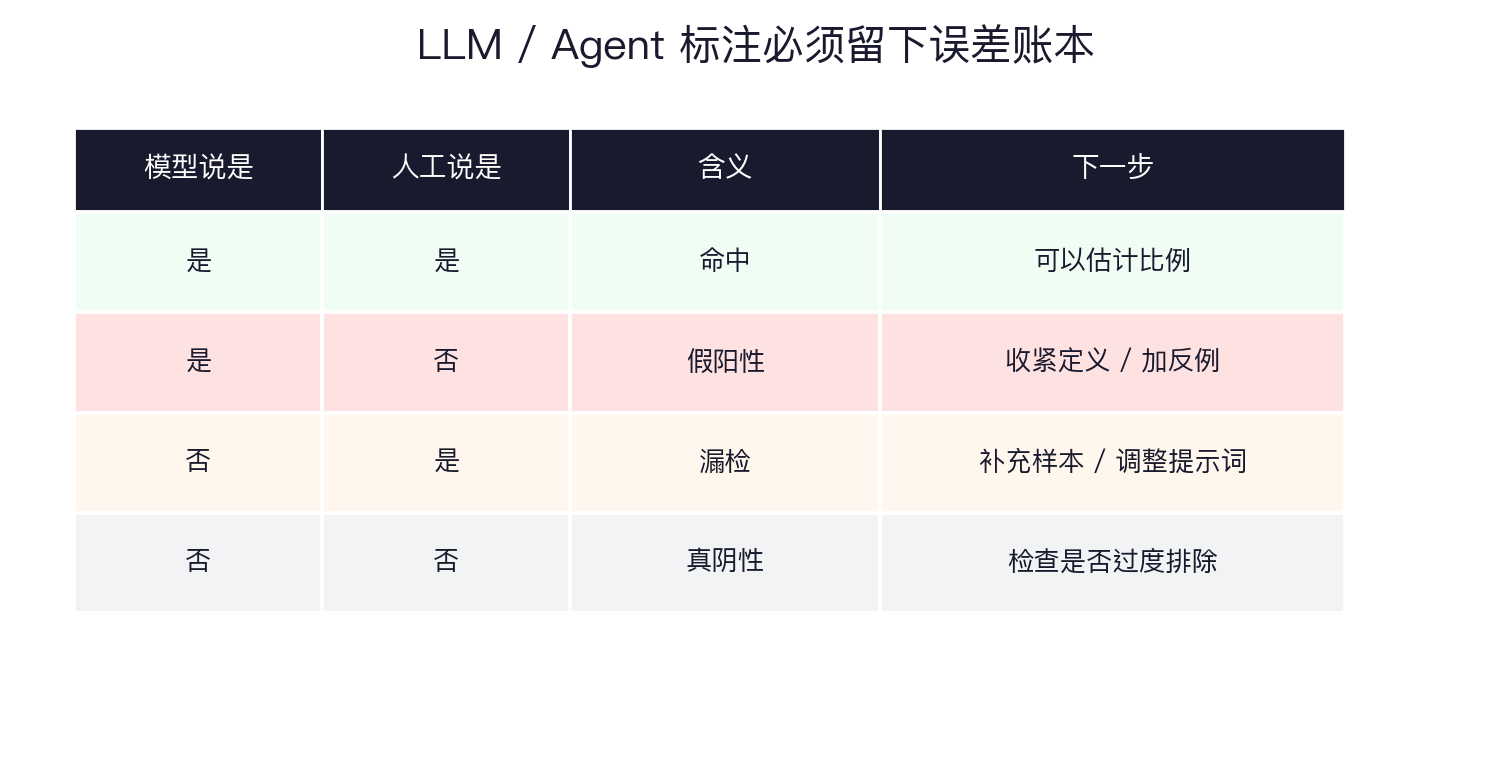
LLM 标注不能省掉误差账本
社交媒体项目可以这样写
| 报告部分 | 你需要交代什么 |
|---|---|
| 研究问题 | 社会现象、理论预期、平台为什么适合观察。 |
| 数据来源 | 平台、时间窗、关键词、采集方式、缺失和限制。 |
| 分析结果 | 内容、网络、时间或多模态信号中的主要发现。 |
| 验证与边界 | 抽检、反例、不能推广到哪里。 |
Part 4 / 4多智能体:Swarm、Team 与 Agent-to-Agent 通信
后半部分只抓三件事
Microsoft AutoGen 给我们的二分法
依据 Microsoft AutoGen 文档:Teams 教程与 Swarm 教程。课堂上把它们理解为两类多智能体组织方式。
一张图记住:Swarm vs Team
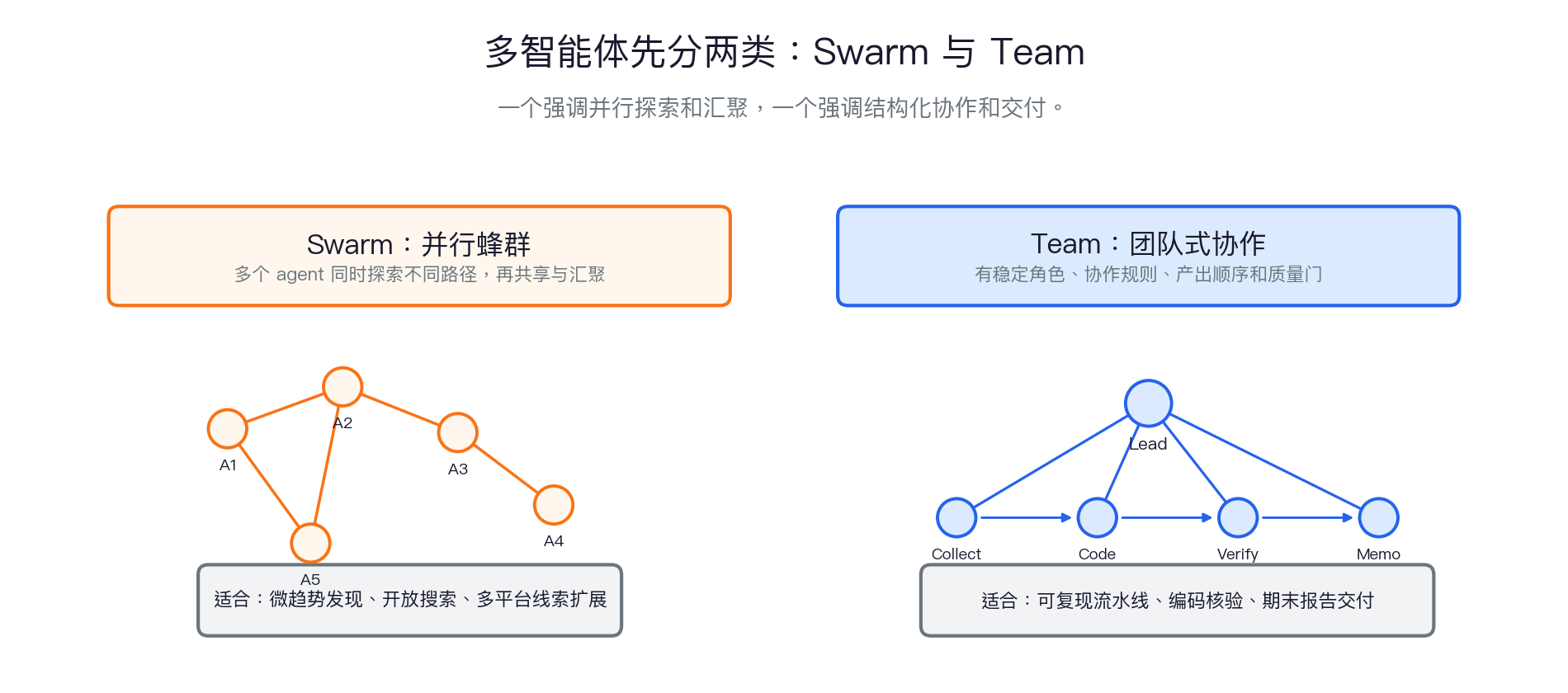
Swarm:核心是并行探索与汇聚
Swarm 的课堂定义:多个 agent 同时从不同角度探索同一个开放问题。
重点不是线性顺序,而是并行展开、共享中间结果、合并冲突结论。
- 并行:不同 agent 同时处理不同假设、工具或信息源。
- 共享:中间发现写入同一个共享状态,而不是只留在各自上下文。
- 汇聚:最后要比较、去重、解决冲突,形成一个合并结果。
- 终止:必须有停止条件,否则并行探索会无限扩散。
Swarm 的并行结构
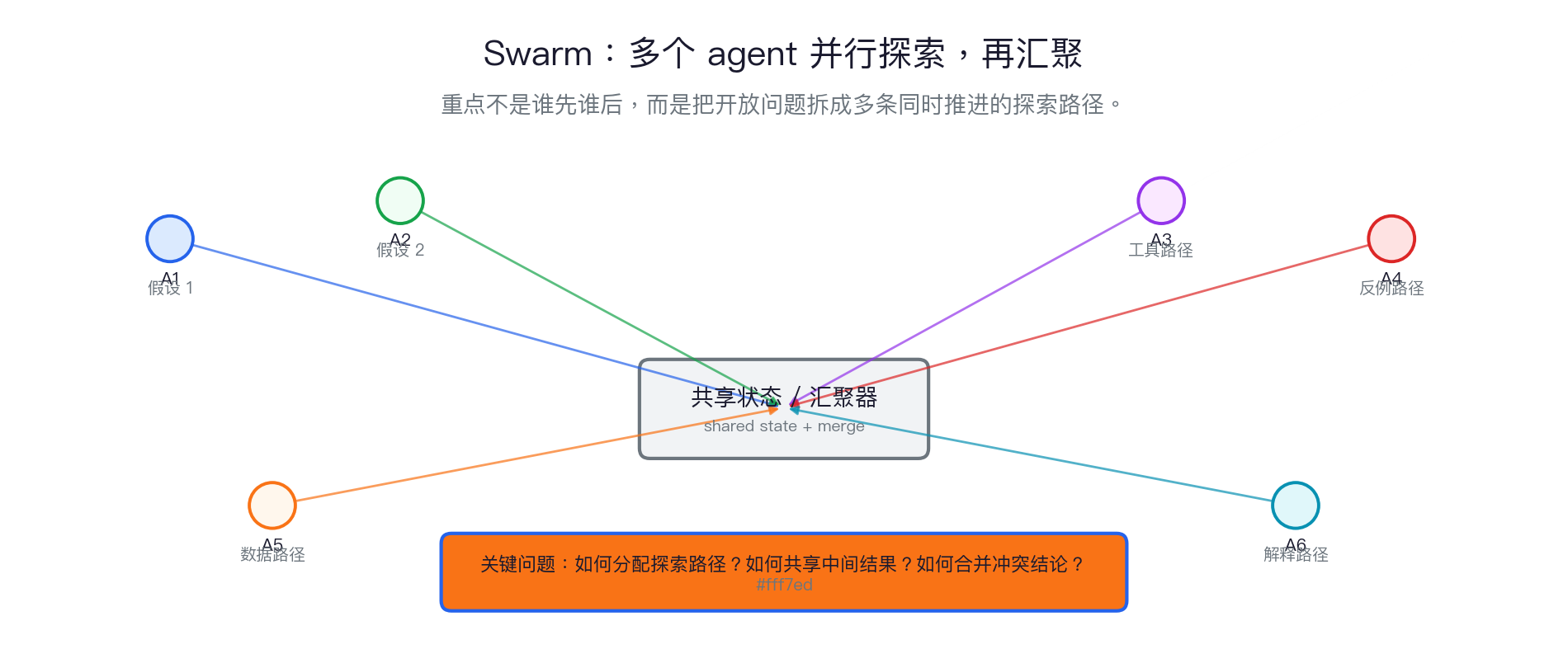
Swarm 适合解决什么问题?
Team:核心是角色、顺序和质量门
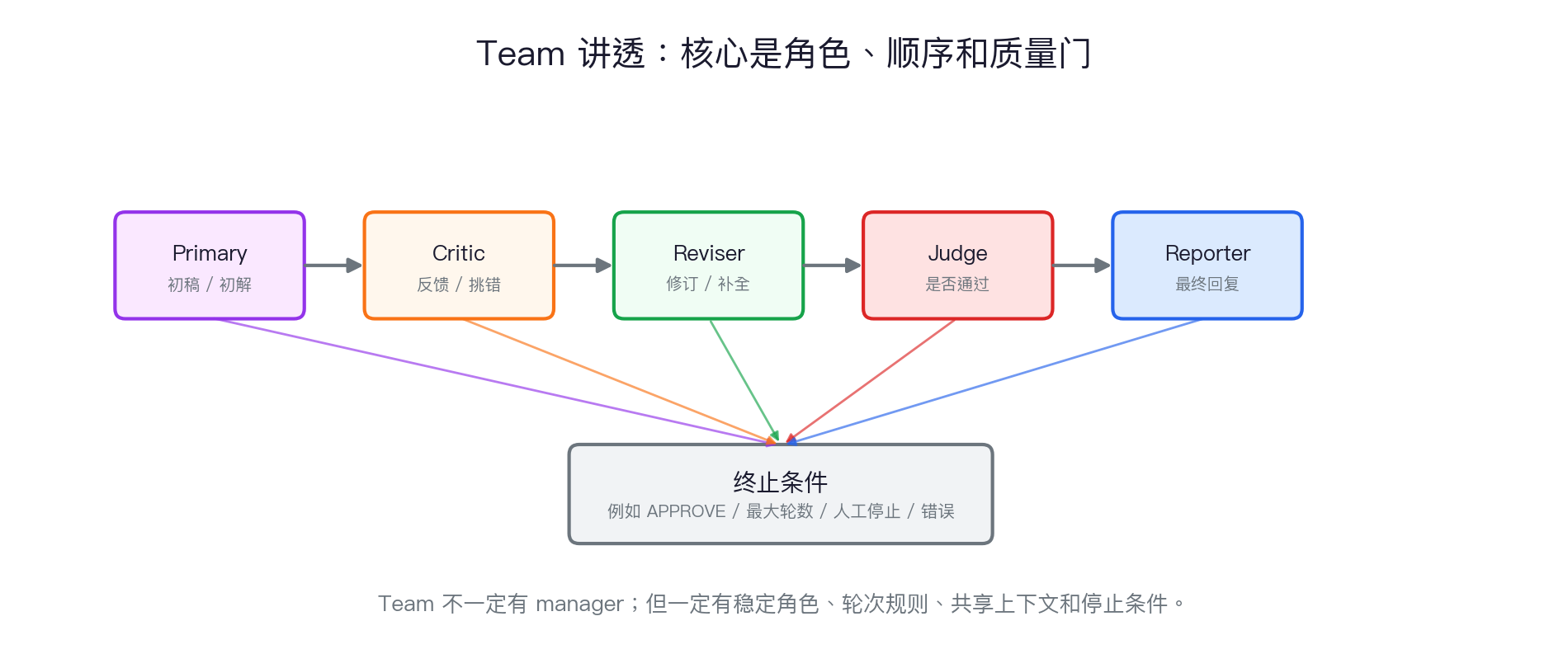
Team 的三个组成部分
AutoGen 的例子:primary agent 写作,critic agent 反馈,直到 critic 输出 APPROVE,团队停止。
Team 的常见运行方式
| Team 类型 | 谁来决定执行结构 | 适合什么任务 | 停止条件 |
|---|---|---|---|
| RoundRobin | 固定轮流 | 写作-批评-修订、教学演示、小组互评 | 出现 APPROVE、达到轮数、人工停止 |
| Selector | 模型或规则选择发言者 | 需要根据上下文选择专家的任务 | 任务完成、无可用下一步、人工停止 |
| Magentic-One | 编排者协调多个 worker | 开放的网页、文件、代码和工具任务 | 编排者判断完成或失败 |
| Swarm | 多个 agent 并行探索后汇聚 | 需要宽搜索、多假设、多工具并行的任务 | 完成汇聚、达到预算或人工停止 |
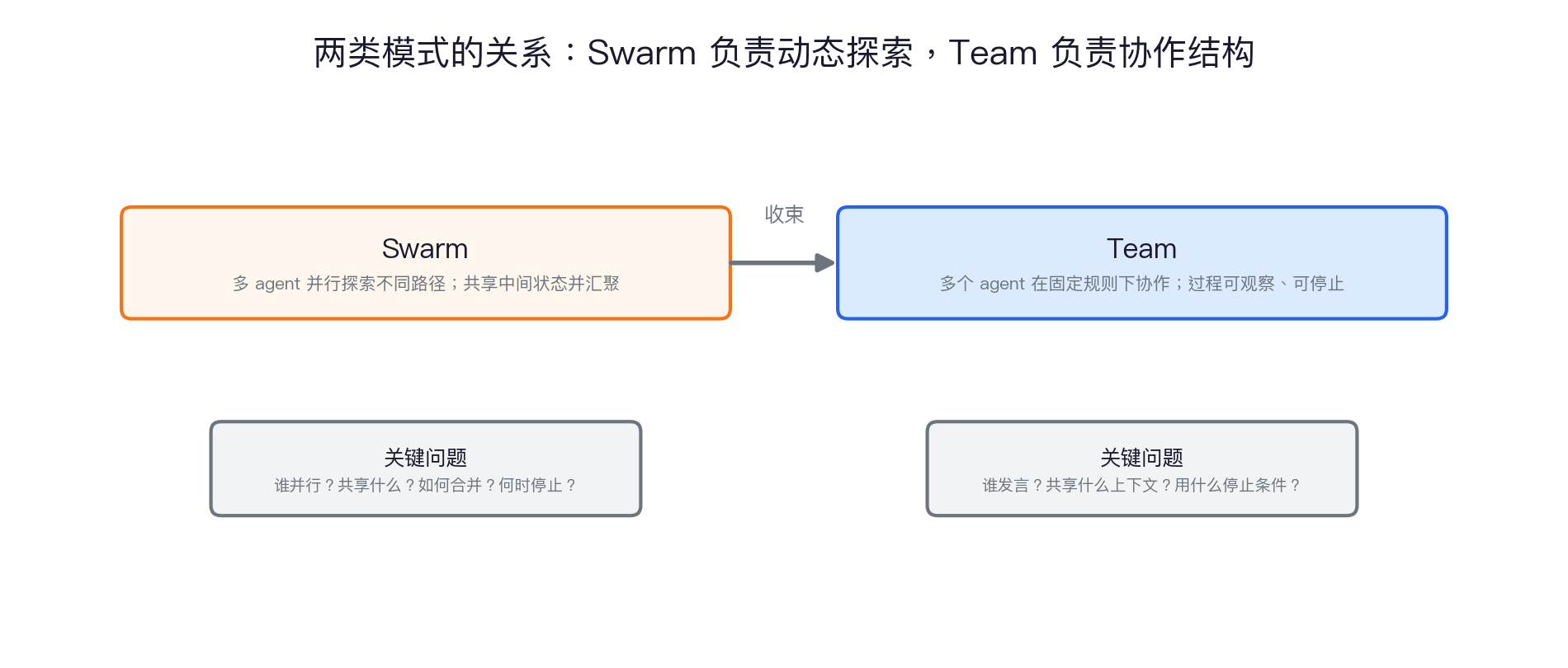
Swarm 和 Team 的关系
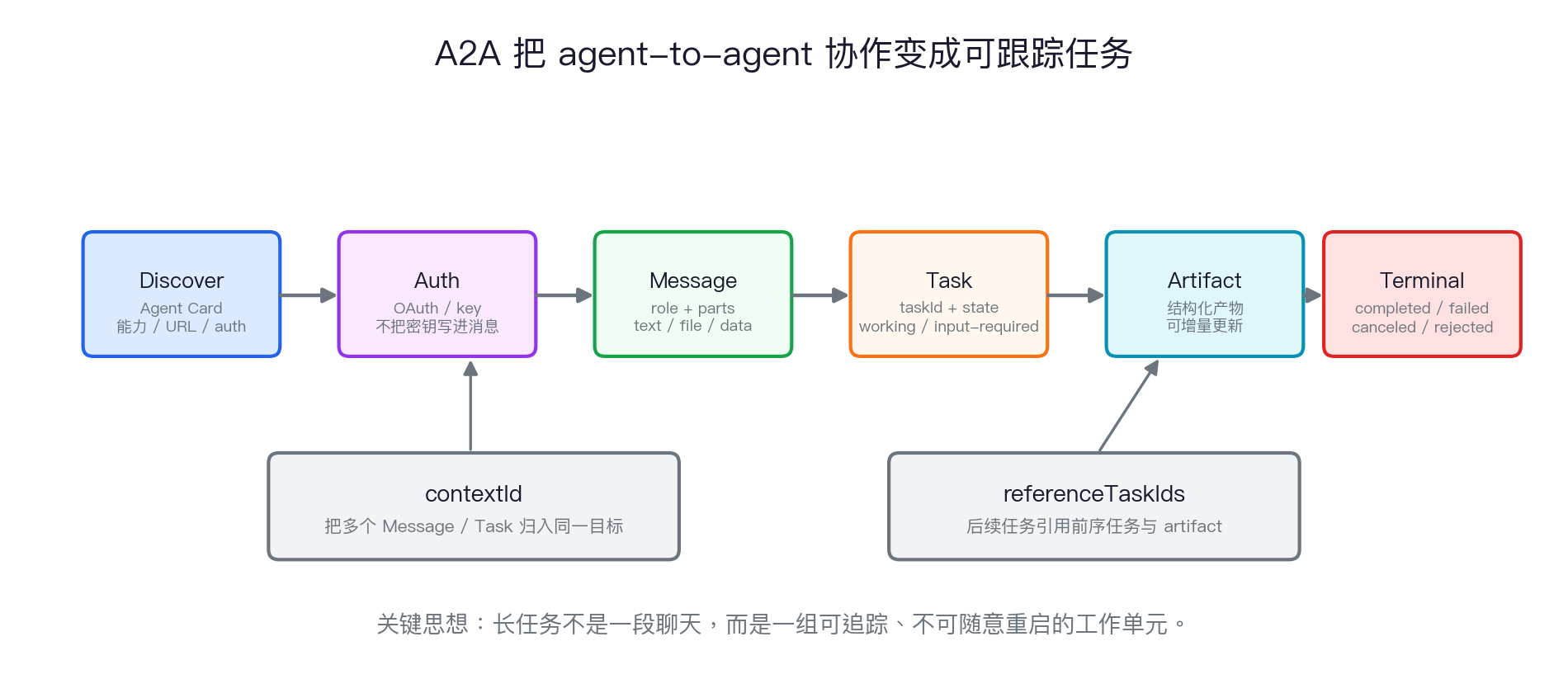
知识点三:Agent-to-Agent Communication
A2A 的五个核心对象
A2A 任务生命周期:从消息到可追踪产物
A2A 是独立的通信层
| A2A 对象 | 它解决的问题 |
|---|---|
| Agent Card | 调用方如何发现一个 agent 的能力、地址、认证方式和输入要求。 |
| Task | 长任务如何拥有 taskId、状态、进度和终止状态,而不是散落在聊天记录里。 |
| Artifact | 结果如何作为结构化产物返回,而不是只返回一段自然语言。 |
| contextId | 同一个目标下的多个 message 和 task 如何保持连续。 |
最后两句:OpenClaw 怎么实现
agentId、workspace、agentDir、session store 和 bindings 让多个 agent 隔离运行。openclaw agent --agent collector --message ... --json 可以直接向某个 agent 发起一次任务。接下来动手操作时,我们只关心两件事:把 agent 配出来;把任务发给正确的 agent。
课堂练习:判断该用 Swarm 还是 Team
答案不是背概念:A 更像 Swarm,因为可以让多个 agent 并行查不同方案;B 更像 Team,因为轮次和停止条件都很清楚。
阅读线索:社交媒体研究
这一页对应前半讲:真实论文图像、平台数据偏差、post-API 数据可得性和极化研究。
阅读线索:多智能体
openclaw agent, sub-agents, multi-agent routing这一页对应后半讲:Swarm、Team、A2A 通信层,以及 OpenClaw 中的一次性 agent 调用。
多智能体的关键
不是数量,是组织方式
Swarm 用并行探索扩大搜索,Team 用角色和质量门稳定产出,A2A 让 agent 之间的任务、状态和 artifact 可追踪。
接下来进入 OpenClaw 动手操作:把 agent 配出来,把任务发给正确的 agent。
Next: OpenClaw hands-on。郑思尧 2026